以GPU为中心的数据包处理,如何克服DPDK限制?
来源:NVIDIA英伟达 发布时间:2023-07-05 11:23:02 阅读量:1192
介绍
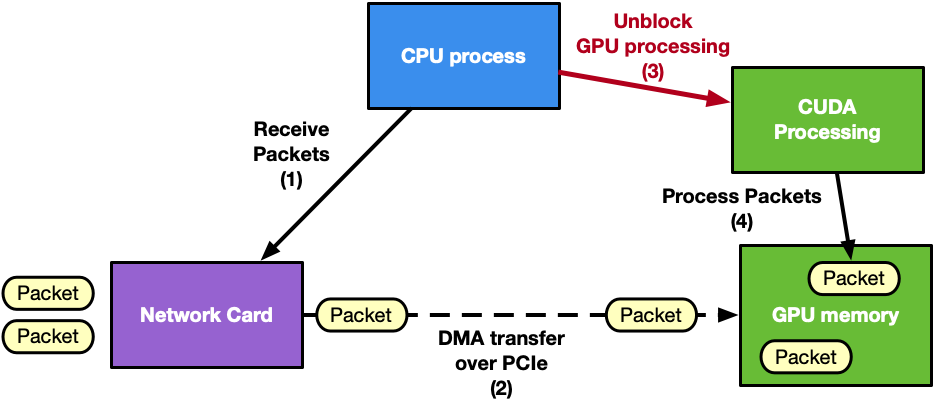
GPU 发起的通信
CPU 调用每个接收队列上的网络功能,以使用一个或多个 CPU 核心接收 GPU 存储器中的数据包 CPU 收集数据包信息(数据包地址、编号) CPU 向 GPU 通知新接收的数据包 GPU 处理数据包
资源消耗:为了处理高速率网络吞吐量(100 Gbps 或更高),应用程序可能需要专用整个 CPU 物理核心来接收(和/或发送)数据包 不可扩展:为了与不同的队列并行接收(或发送),应用程序可能需要使用多个 CPU 核心,即使在 CPU 核心的总数可能被限制在较低数量(取决于平台)的系统上也是如此 平台依赖性:低功耗 CPU 上的同一应用程序将降低性能
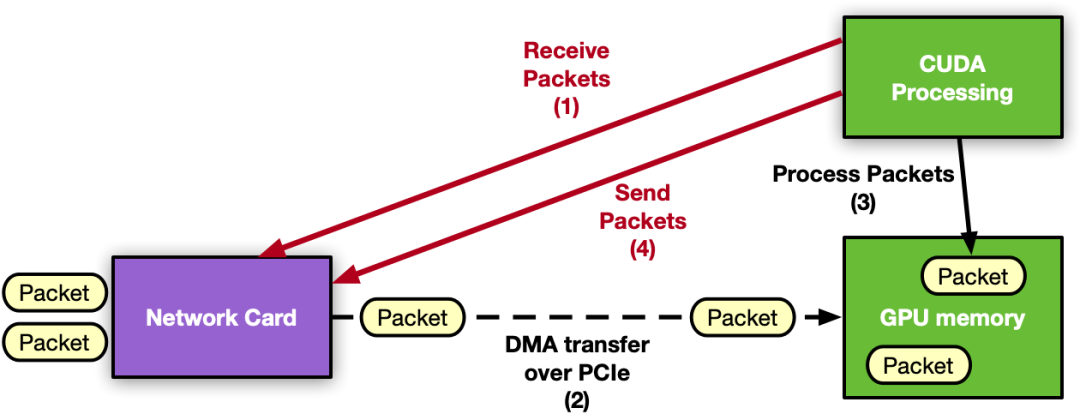
NVIDIA DOCA GPUNetIO 库
GPU 发起的通信: CUDA 内核可以调用 DOCA GPUNetIO 库中的 CUDA device 函数,以指示网卡发送或接收数据包 精确的发送调度:通过 GPU 发起的通信,可以根据用户提供的时间戳来调度未来的数据包传输 GPU Direct RDMA :以连续固定大小 GPU 内存步幅接收或发送数据包,无需 CPU 内存暂存副本 信号量:在 CPU 和 GPU 之间或不同 GPU CUDA 内核之间提供标准化的低延迟消息传递协议 CPU 对 CUDA 内存的直接访问:CPU 可以在不使用 GPU 内存 API 的情况下修改 GPU 内存缓冲区
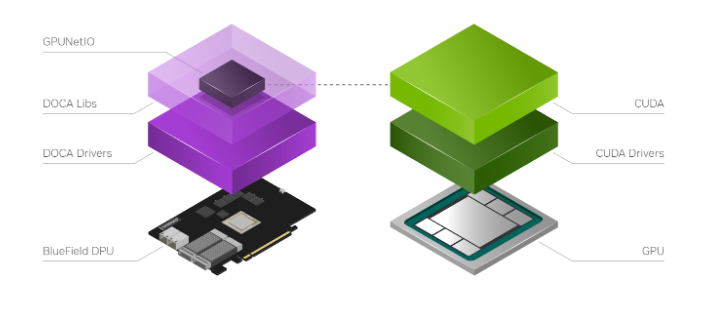
使用 DOCA 识别和初始化 GPU 设备和网络设备 使用 DOCA GPUNetIO 创建可从 CUDA 内核管理的接收或发送队列 使用 DOCA Flow 确定应在每个接收队列中放置哪种类型的数据包(例如,IP 地址的子集、TCP 或 UDP 协议等) 启动一个或多个 CUDA 内核(执行数据包处理/过滤/分析)
使用 DOCA GPUNetIO CUDA 设备函数发送或接收数据包 使用 DOCA GPUNetIO CUDA 设备函数与信号量交互,以使工作与其他 CUDA 内核或 CPU 同步
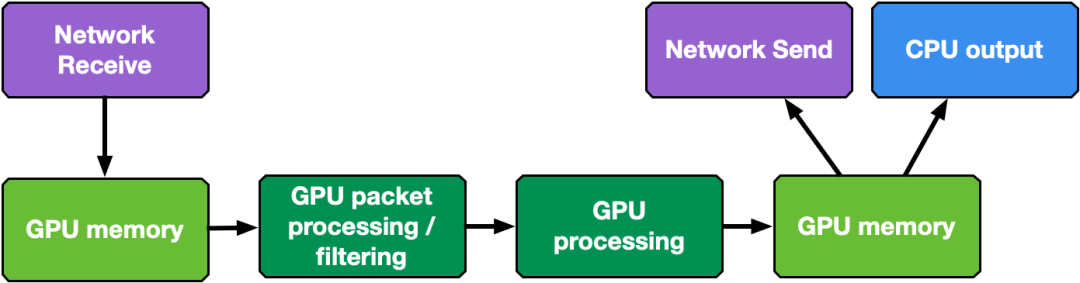
CPU 接收和 GPU 处理
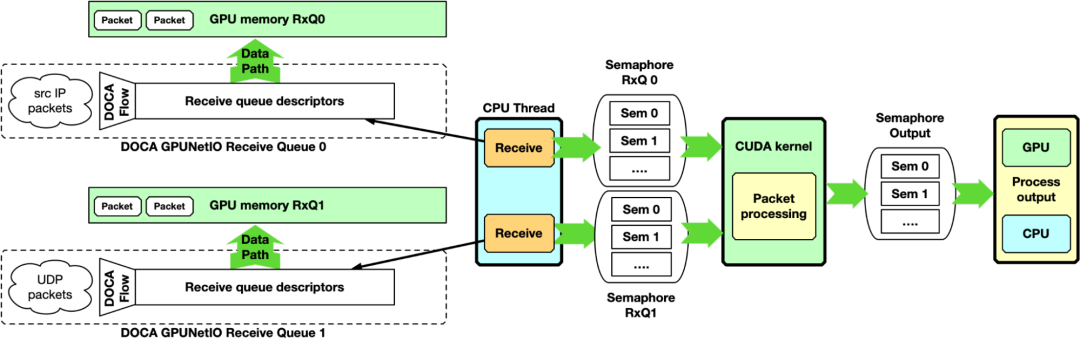
GPU 接收和 GPU 处理
多 CUDA 内核
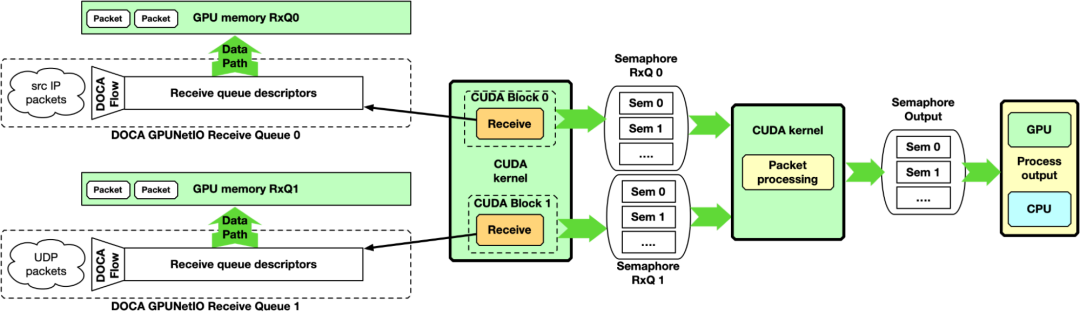
单 – CUDA 内核
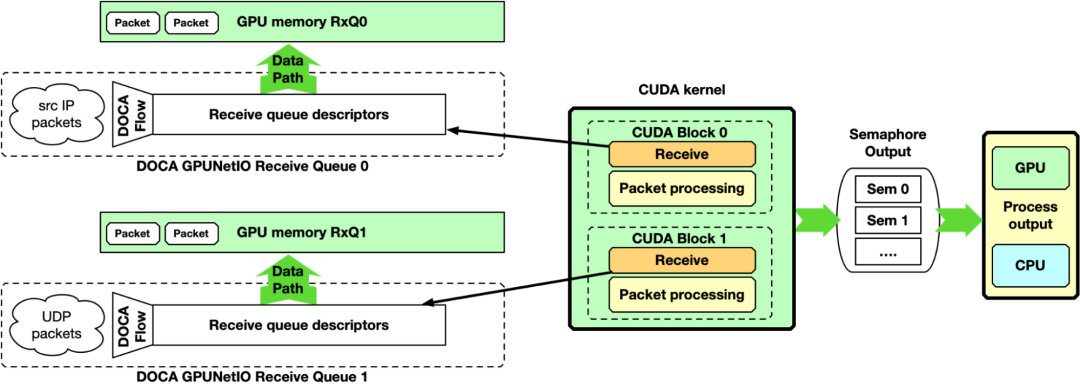
GPU 接收、 GPU 处理和 GPU 发送
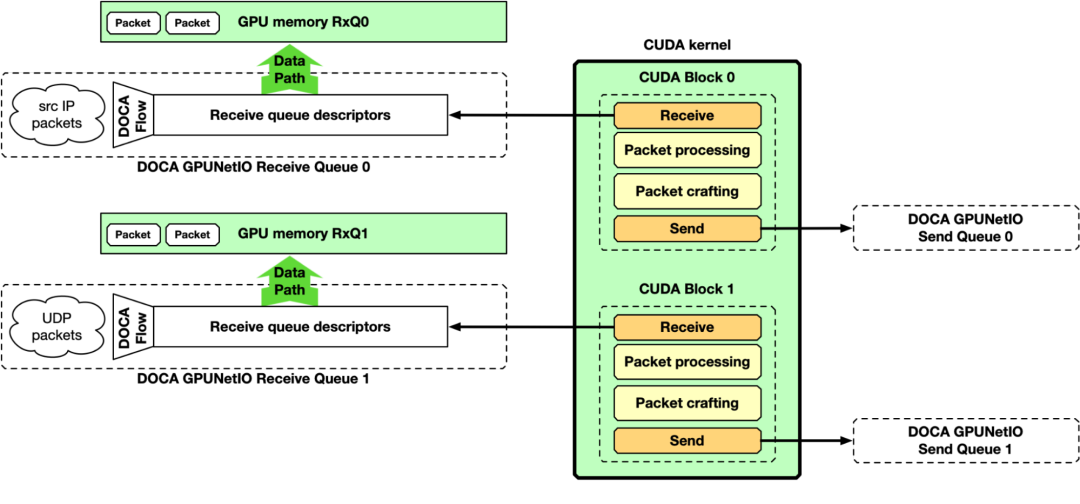
NVIDIA DOCA GPUNetIO 示例应用程序
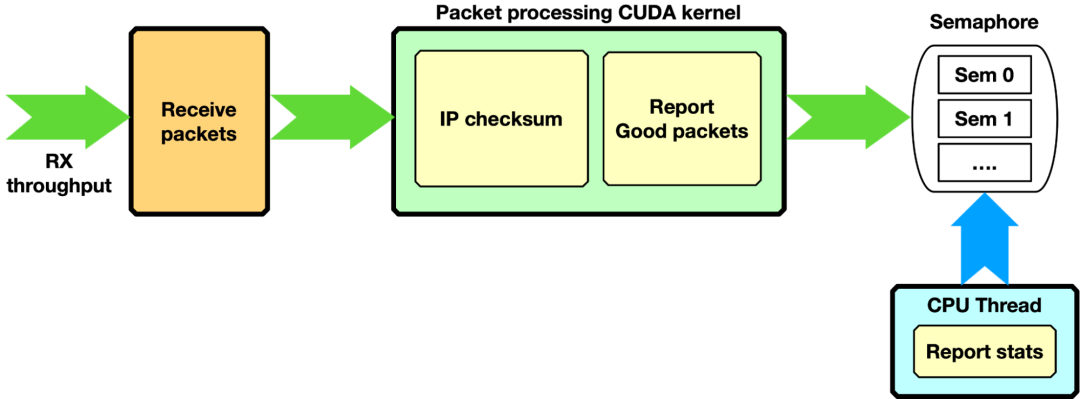
IP 校验和, GPU 仅接收
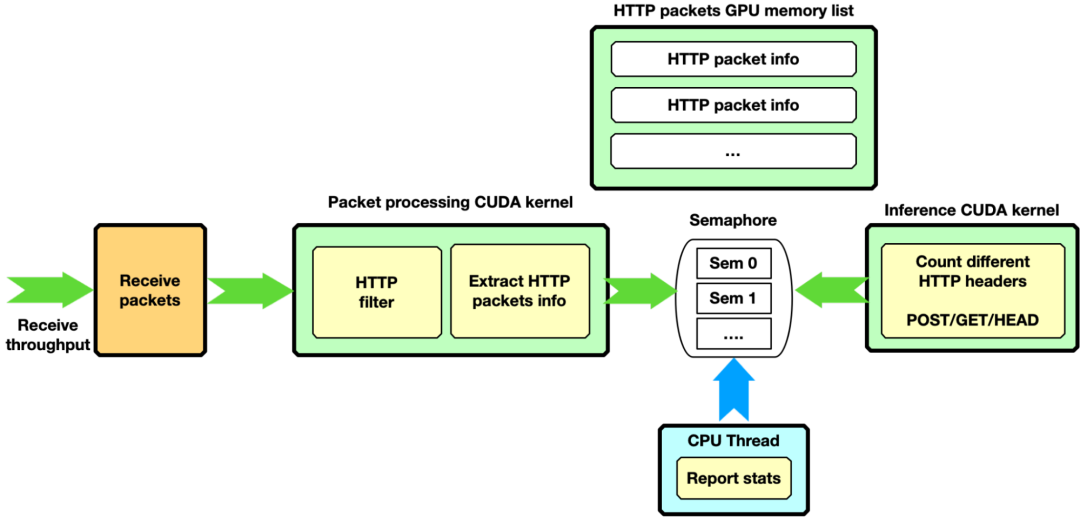
HTTP 过滤, GPU 仅接收
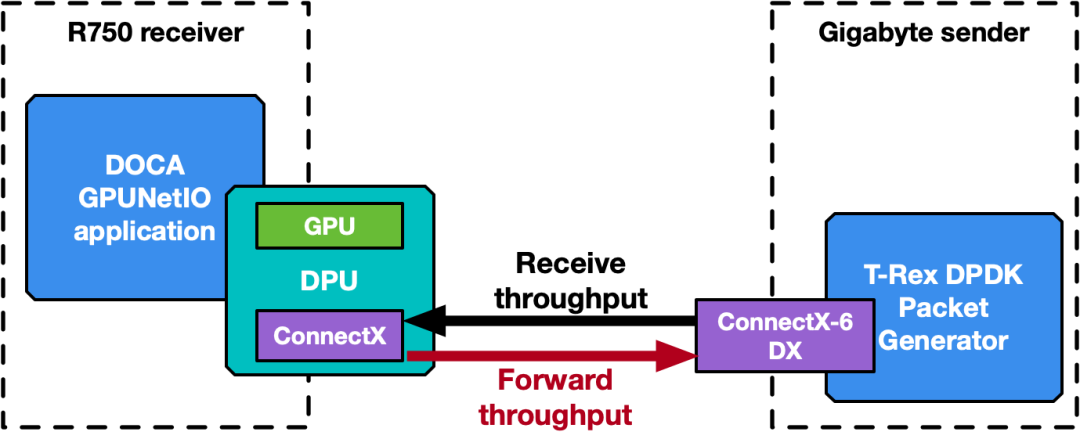
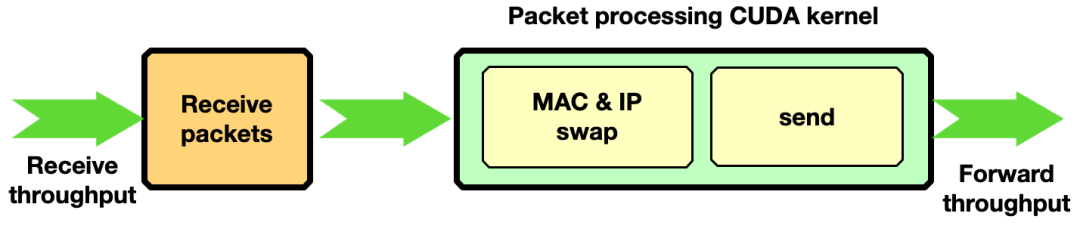
流量转发
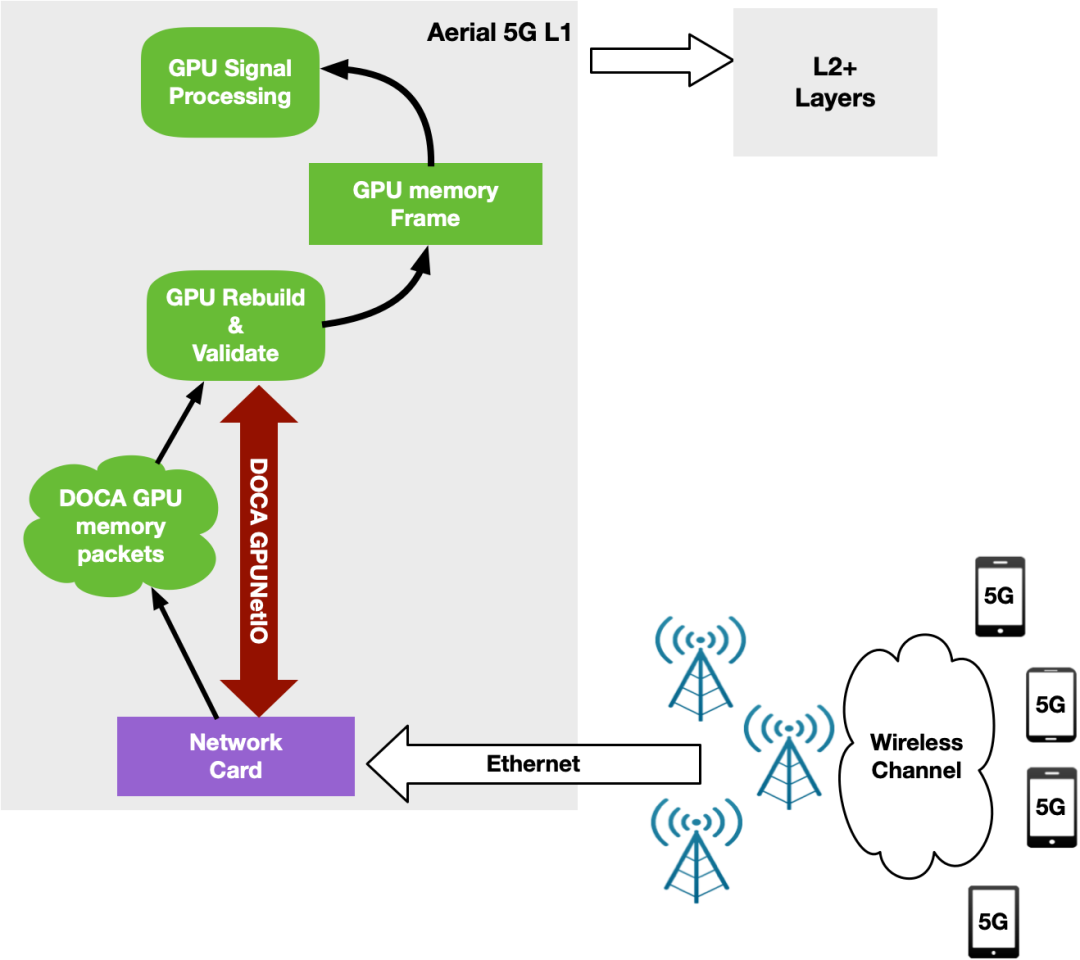
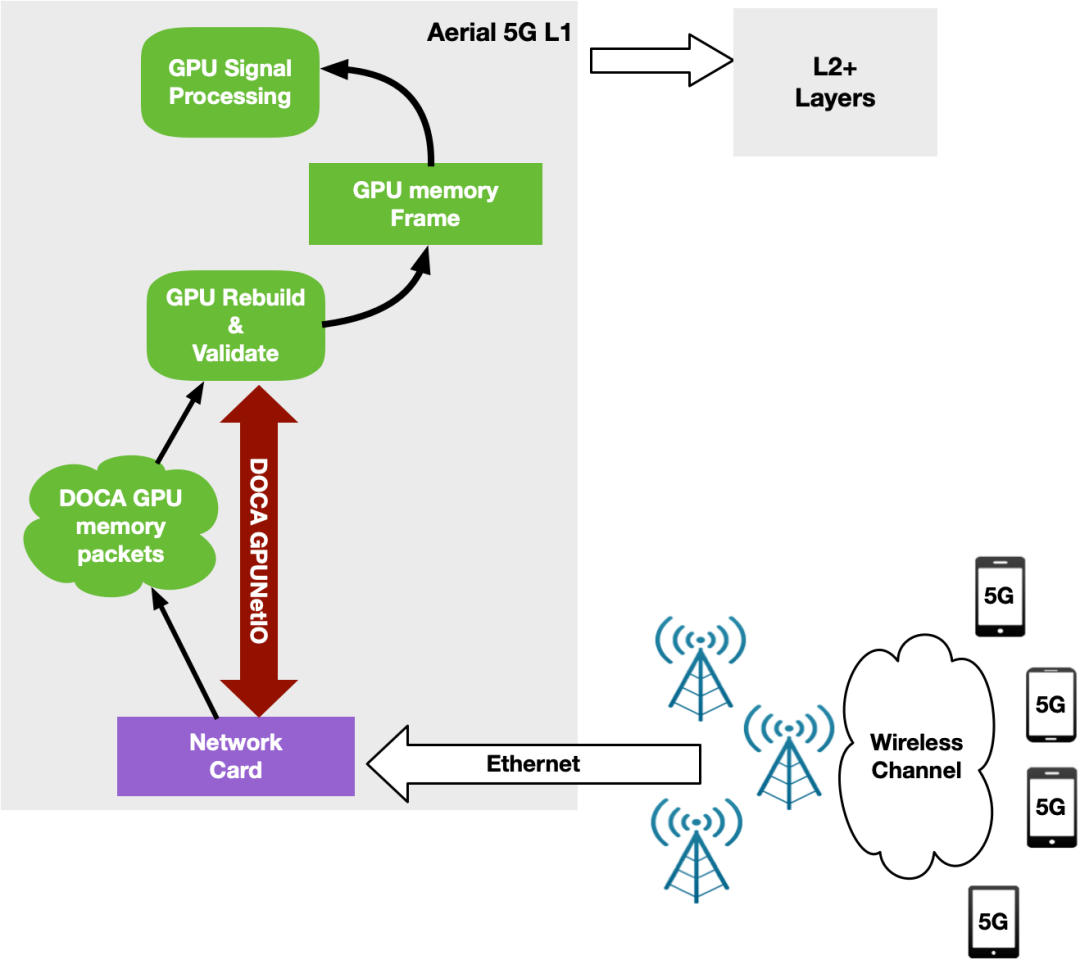
用于 5G 的 NVIDIA Aerial SDK
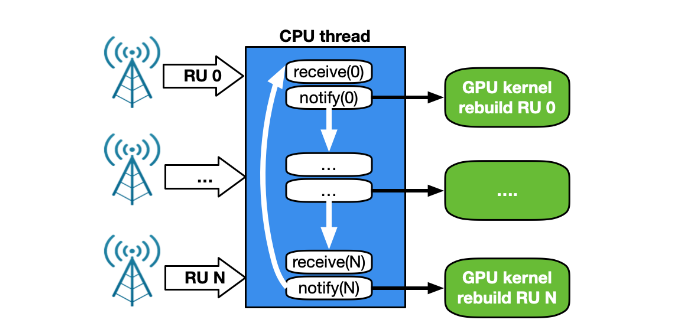
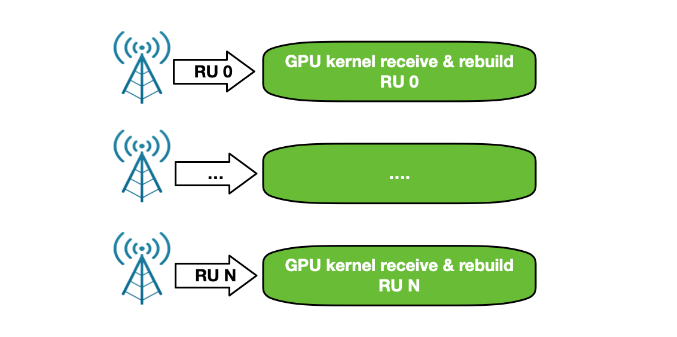
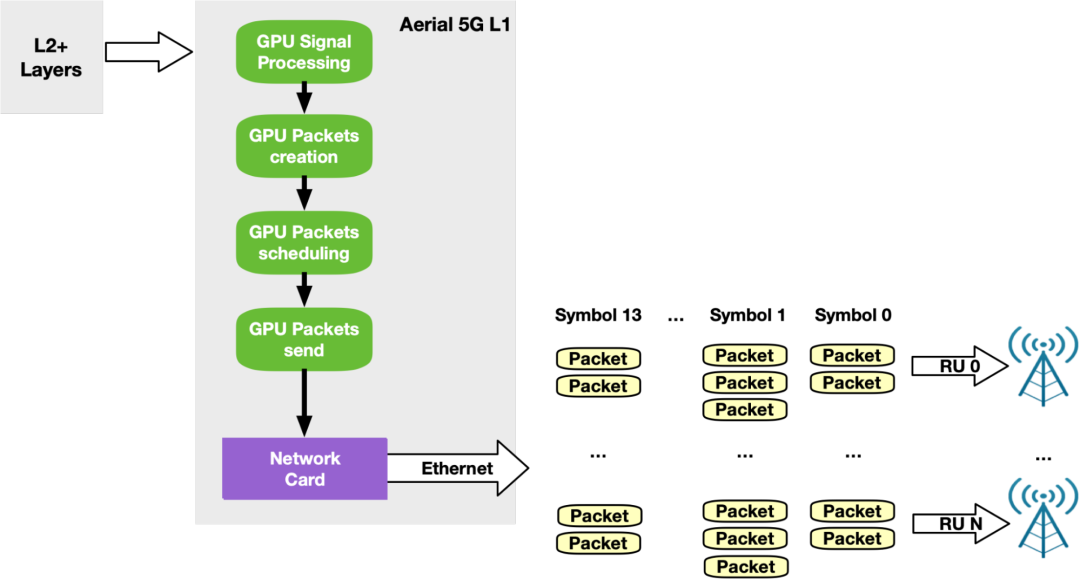
尽早访问 NVIDIA DOCA GPUNetIO
应用程序初始设置阶段的一组 CPU 函数,用于准备环境并创建队列和其他对象 您可以在 CUDA 内核中调用一组特定于 GPU 的函数,以发送或接收数据包,并与 DOCA GPUNetIO 信号量交互 您可以构建和运行应用程序源代码来测试功能,并了解如何使用 DOCA GPUNetIO API