一种用于私募 AI HPC 集群的 GPU 监控方案
来源:少年炼金 发布时间:2023-07-28 17:25:34 阅读量:817
如今,GPU 领域玩起了“文艺复兴”!私募很显然,没办法利用云厂商的 GPU,因为性能太低了,大部分实现原理还都是池化后远程 API 转发方案或者 MIG,一个函数调用延迟可达 5ms 以上。RDMA 也很难拯救 AI 模型的训练的网络延迟,更多的还是直接“交电费” —— 买物理机直接裸金属调度。 OpenAI 推出的 GPT 4.0 没有开放大概率是因为模型是可复制的,4.5亿就可以训练一个 GPT 4.0,更多是拼的火电厂中的煤炭储量。
本文将介绍如何在 NVIDIA 和 AMD 这两种品牌的 GPU 构建性能指标监控。由于 AMD 在软件生态上的缺陷,只开源了个 ROCm,而且也只有 ROCm...,那么也就剩下 SMI 可以用用了。
现阶段,大部分金融机构更多的是使用 A100 的 NVIDIA GPU,H100 还没有推出。 
从数据中心和云到桌面和边缘,NVIDIA Cloud Native 技术提供了在配备 NVIDIA GPU 的系统上运行深度学习、机器学习和由 Kubernetes 管理的其他 GPU 加速工作负载的能力,并开发可用于无缝部署在企业云原生管理框架上。NVIDIA 积极的拥抱了 Kubernetes,并且提供了深度的集成: 对于管理 AI 或 HPC 工作负载的大规模 GPU 集群的基础设施或站点可靠性工程 (SRE) 团队来说,监控 GPU 至关重要。GPU 指标使团队能够了解工作负载行为,从而优化资源分配和利用率、诊断异常并提高数据中心的整体效率。除了基础设施团队之外,无论您是从事 GPU 加速的 ML 工作流程的研究人员,还是喜欢了解容量规划的 GPU 利用率和饱和度的数据中心设计人员,您可能也对指标感兴趣。 随着 AI/ML 工作负载使用 Kubernetes 等容器管理平台进行容器化和扩展,这些趋势变得更加重要。在这篇文章中,我们概述了 NVIDIA 数据中心 GPU 管理器 (DCGM),以及如何将其集成到 Prometheus 和 Grafana 等开源工具中,以形成 Kubernetes GPU 监控解决方案的构建块。 NVIDIA DCGM
NVIDIA 数据中心 GPU 管理器 (DCGM) 是一套用于在集群环境中管理和监控 NVIDIA 数据中心 GPU 的工具。它包括主动健康监控、全面诊断、系统警报和治理策略(包括电源和时钟管理)。它可以由基础设施团队独立使用,也可以轻松集成到 NVIDIA 合作伙伴的集群管理工具、资源调度和监控产品中。
DCGM 简化了数据中心的 GPU 管理,提高了资源可靠性和正常运行时间,自动执行管理任务,并帮助提高整体基础设施效率。DCGM 支持 x86_64、Arm 和 POWER (ppc64le) 平台上的 Linux 操作系统。安装程序包包括库、二进制文件、NVIDIA 验证套件 (NVVS) 以及使用 API(C、Python 和 Go)的源示例。DCGM 还使用 DCGM Exporter 集成到 Kubernetes 生态系统中,以在容器化环境中提供丰富的 GPU 遥测。
存储库在这里:https://github.com/NVIDIA/DCGM,文档在这里:https://docs.nvidia.com/datacenter/dcgm/latest/,笔者在 Ubuntu Server 上安装:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.0-1_all.debsudo dpkg -i cuda-keyring_1.0-1_all.debsudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /"sudo apt-get updatesudo apt-get install -y datacenter-gpu-managersudo systemctl --now enable nvidia-dcgmdcgmi discovery -l # 您应该会看到系统中找到的所有支持的 GPU(以及任何 NVSwitch)的列表
DCGM 应该在虚拟机或者物理机上安装,而不是容器环境。
监控堆栈通常由收集器、用于存储指标的时间序列数据库和可视化层组成。Prometheus是一个流行的开源堆栈,它与Grafana一起用作可视化工具来创建丰富的仪表板。Prometheus 还包括Alertmanager来创建和管理警报。Prometheus 与kube-state-metrics和node_exporter一起部署,以公开 Kubernetes API 对象的集群级指标和节点级指标(例如 CPU 利用率)。
在前面描述的 Go API 的基础上,您可以使用 DCGM 将 GPU 指标公开给 Prometheus。dcgm-exporter 使用 Go 绑定从 DCGM 收集 GPU 遥测数据,然后公开 Prometheus 使用 HTTP 端点 (/metrics) 提取的指标。dcgm-exporter 也是可配置的。您可以使用 .csv 格式的输入配置文件自定义 DCGM 收集的 GPU 指标。
dcgm-exporter 收集节点上所有可用 GPU 的指标。然而,在 Kubernetes 中,您可能不一定知道当 Pod 请求 GPU 资源时,节点中的哪些 GPU 会被分配给 Pod。从 v1.13 开始,kubelet添加了设备监控功能,可让您使用 pod-resources 套接字查找分配给 Pod 的设备(Pod名称、Pod 命名空间和设备 ID)。dcgm-exporter 中的 HTTP 服务器连接到kubelet 的 Pod 资源服务器 (/var/lib/kubelet/pod-resources) 以识别 Pod 上运行的 GPU 设备,并将 GPU 设备 Pod 信息附加到收集的指标中。
以下是一些 dcgm-exporter 设置示例 。如果您使用 NVIDIA GPU Operator,则 dcgm-exporter 是作为该 Operator 的一部分部署的组件之一。我们现在在一个已经就绪的 Kubernetes 集群中安装 Prometheus:
helm repo add prometheus-community https://prometheus-community.github.io/helm-chartshelm repo updatehelm inspect values prometheus-community/kube-prometheus-stack > /tmp/kube-prometheus-stack.valueshelm install prometheus-community/kube-prometheus-stack --create-namespace --namespace prometheus --generate-name --set prometheus.service.type=NodePort --set prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=falsekubectl get pods -Akubectl get svc -A
helm repo add gpu-helm-charts https://nvidia.github.io/gpu-monitoring-tools/helm-chartshelm repo updatehelm install --generate-name gpu-helm-charts/dcgm-exporterhelm lskubectl get svc -A
使用暴露在32032端口的Grafana服务,访问Grafana主页。使用 Prometheus 图表中提供的凭据登录仪表板:adminPassword 中的字段 prometheus.values。现在要启动用于 GPU 指标的 Grafana 仪表板,请从Grafana Dashboards导入参考 NVIDIA 仪表板,具体的内容在这里:https://grafana.com/grafana/dashboards/12239-nvidia-dcgm-exporter-dashboard/。
现在运行一些GPU工作负载。为此,DCGM包括一个名为 dcgmproftester 的CUDA负载生成器。它可用于生成确定性CUDA工作负载,用于读取和验证GPU度量。我们有一个容器化的 dcgmproftester,您可以使用它,在Docker命令行上运行。此示例生成半精度(FP16)矩阵乘法(GEMM)并使用GPU上的张量核。要生成负载,您必须首先下载DCGM并将其容器化。以下脚本创建了一个可用于运行dcgmproftester的容器。此容器可在NVIDIA DockerHub存储库中找到。
#!/usr/bin/env bashset -exo pipefailmkdir -p /tmp/dcgm-dockerpushd /tmp/dcgm-dockercat > Dockerfile <<EOFARG BASE_DISTARG CUDA_VERFROM nvidia/cuda:\${CUDA_VER}-base-\${BASE_DIST}LABEL io.k8s.display-name="NVIDIA dcgmproftester"ARG DCGM_VERSIONWORKDIR /dcgmRUN apt-get update && apt-get install -y --no-install-recommends \libgomp1 \wget && \rm -rf /var/lib/apt/lists/* && \wget --no-check-certificate https://developer.download.nvidia.com/compute/redist/dcgm/\${DCGM_VERSION}/DEBS/datacenter-gpu-manager_\${DCGM_VERSION}_amd64.deb && \dpkg -i datacenter-gpu-manager_*.deb && \rm -f datacenter-gpu-manager_*.debENTRYPOINT ["/usr/bin/dcgmproftester11"]EOFDIR=.DCGM_REL_VERSION=2.0.10BASE_DIST=ubuntu18.04CUDA_VER=11.0IMAGE_NAME=nvidia/samples:dcgmproftester-$DCGM_REL_VERSION-cuda$CUDA_VER-$BASE_DISTdocker build --pull \-t "$IMAGE_NAME" \--build-arg DCGM_VERSION=$DCGM_REL_VERSION \--build-arg BASE_DIST=$BASE_DIST \--build-arg CUDA_VER=$CUDA_VER \--file Dockerfile \"$DIR" popd
在Kubernetes集群上部署容器之前,请尝试在Docker中运行它。在本例中,通过指定-t 1004,使用张量核心触发FP16矩阵乘法,并运行测试-d 45(45秒)。您可以通过修改-t参数来尝试运行其他工作负载。
docker run --rm --gpus all --cap-add=SYS_ADMIN nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04 --no-dcgm-validation -t 1004 -d 45将其安排到您的Kubernetes集群中,并在Grafana仪表板中查看相应的指标。以下代码示例使用容器的适当参数构造了这个podspec:
cat << EOF | kubectl create -f -apiVersion: v1kind: Podmetadata:name: dcgmproftesterspec:restartPolicy: OnFailurecontainers:- name: dcgmproftester11image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04args: ["--no-dcgm-validation", "-t 1004", "-d 120"]resources:limits:nvidia.com/gpu: 1securityContext:capabilities:add: ["SYS_ADMIN"]EOFkubectl get pods -A
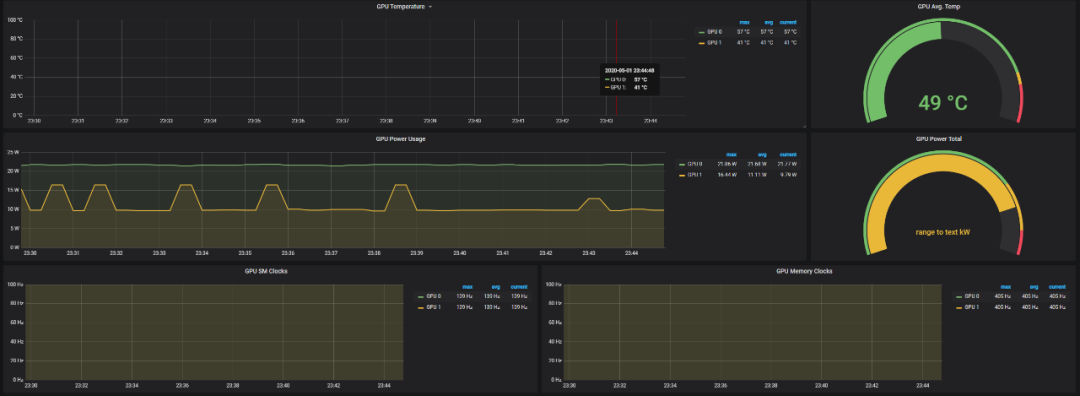
您可以看到dcgmproftester Pod正在运行,然后是Grafana仪表板上显示的指标。GPU利用率(GrActive)已达到98%的峰值。您还可能会发现其他指标很有趣,例如功率或GPU内存。
DCGM最近添加了一些设备级指标。其中包括细粒度的GPU利用率指标,可以监控SM占用率和张量核利用率。有关更多信息,请参阅《DCGM用户指南》中的评测指标。为了方便起见,当您使用Helm Charts部署dcgm-exporter时,默认情况下会将其配置为收集这些指标。
DCGM API文档中提供了GPU指标。通过使用GPU指标作为自定义指标和Prometheus Adapter,您可以使用Horizontal Pod Autoscaler根据GPU利用率或其他指标缩放 Pod 数量。
不幸的是,只有分析指标仅限于数据中心(以前的“Tesla”)品牌 GPU,例如 A100、V100 和 T4。但是,您仍然可以使用 dcgm-exporter 来访问 GTX 和 RTX 系列上的其他 GPU 遥测。为此,您必须在安装过程中覆盖 Helm 图表中的“arguments”变量并将其设置为 nil。例如,您可以直接在Helm图表中修改values.yaml。
helm install --generate-name gpu-helm-charts/dcgm-exporter --set arguments=nullNVIDIA 并不像 AMD 那样缺少软件支持,因此你可以通过 Golang 或者 Python 接入自己的监控系统。NVIDIA 提供了 NVML 的 Golang 绑定:https://github.com/NVIDIA/go-nvml 和 DCGM 的 Golang 绑定:https://github.com/NVIDIA/go-dcgm。
此外,Kubernetes 通过 Device Plugin Framework 提供对 NVIDIA GPU、NIC、Infiniband 适配器和其他设备等特殊硬件资源的访问。然而,使用这些硬件资源配置和管理节点需要配置多个软件组件,例如驱动程序、容器运行时或其他库,这些组件很难并且容易出错。NVIDIA GPU Operator 使用Kubernetes中的 Operator Framework 来自动管理提供GPU所需的所有NVIDIA软件组件。这些组件包括NVIDIA驱动程序(用于启用CUDA)、用于GPU的Kubernetes设备插件、NVIDIA容器运行时、自动节点标记、基于DCGM的监控等。GPU Operator 允许 Kubernetes 集群的管理员像管理集群中的 CPU 节点一样管理 GPU 节点。管理员无需为 GPU 节点配置特殊的操作系统映像,而是可以依赖 CPU 和 GPU 节点的标准操作系统映像,然后依靠 GPU Operator 为 GPU 配置所需的软件组件。请注意,GPU Operator 对于 Kubernetes 集群需要快速扩展的场景特别有用,例如在云端或本地配置额外的 GPU 节点以及管理底层软件组件的生命周期。由于 GPU Operator 将所有内容作为容器运行(包括 NVIDIA 驱动程序),因此管理员只需启动或停止容器即可轻松交换各种组件。存储库地址:https://github.com/NVIDIA/gpu-operator。
笔者推荐直接使用 NVML 和 ROCm 的 SMI 动态库构建指标导出器,由于读取 GPU 的某些指标可能存在较大的延迟和性能瓶颈,可以采用在线下发监控规则给指标导出器或者通过 --enable-xxx 选项实现开启,前者需要系统支持,后者需要重启指标导出器进程。
我的 HPC 集群中使用自研的指标导出器、Promethues、Grafana、Discord 机器人 和自研的监控规则下发系统实现监控,并且自研的 GPU 导出器牺牲了安全性来换取性能,使用 Golang 提供的 unsafe 的方式读取 NVML 和 ROCm 数据。