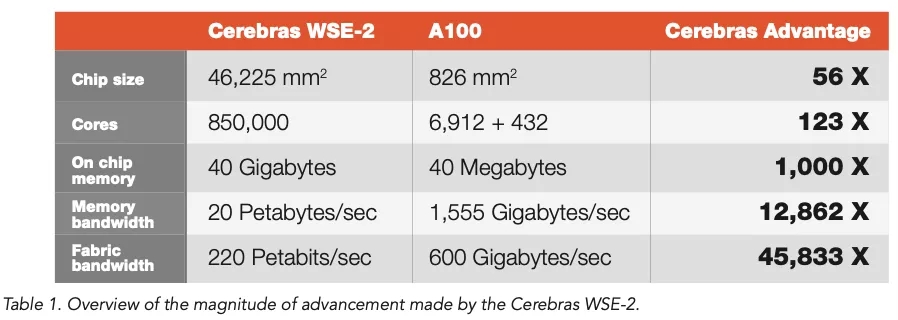
这家初创公司为其计算机系列增加了一台内存机器和一台fabric switch,支持由多达 192 台专用 AI 计算机组成的集群系统。Cerebras为之前宣布的CS-2 AI计算机添加了一款新的交换机产品SwarmX(该产品同时拥有路由功能和计算功能)以及一台含有2.4 PB DRAM和NAND的内存计算机(名为 MemoryX)。
CS-2的内部示意图。从左到右是:面板、风扇、泵、电源装置、主机箱、热交换器、引擎组和后格栅。

CS-2的引擎组
深度学习形式的AI正在催生拥有数万亿个神经权重或参数的神经网络,越来越庞大的规模给用于开发此类神经网络的软硬件带来了难题。AI系统制造商Cerebras Systems的联合创始人兼首席执行官Andrew Feldman采访时概述了神经网络的近期发展史,表示“短短两年内,模型变大了 1000 倍,模型所需的计算量也增加了 1000 倍。”Feldman的公司在一年一度的面向先进计算的Hot Chips计算机芯片大会上推出新计算机。今年该大会在网上举行,Cerebras发布了宣布新计算机的新闻稿。Cerebras与AI领导者英伟达以及Graphcore和SambaNova Systems等其他AI初创公司相竞争,旨在训练这些日益庞大的网络时取得领先的性能。训练是开发神经网络程序的阶段,开发所采用的手段是馈送大量数据,反复调整神经网络权重,直至获得最高的准确度。神经网络的规模一直在稳步增长,这在业内里不是什么秘密。在去年,OpenAI的GPT-3自然语言处理程序虽拥有1750亿个权重,但与谷歌拥有1.6万亿个参数的模型Switch Transformer相比黯然失色。按神经权重来衡量GPT-3曾是全球最庞大的神经网络。如此庞大的模型之所以遇到问题,是由于它们超出了单个计算机系统所能处理的极限。单个GPU的内存约16GB,远远满足不了GPT-3等模型需要的可能多达数百TB的内存。因此,将系统集群起来变得至关重要。而如何集群成为了关键问题,因为每台机器都必须保持忙碌状态,否则利用率会下降。比如说,今年英伟达、斯坦福大学和微软共同创建了一个有1万亿个参数的GPT-3版本,并将其扩展到3072个GPU。但是利用率(即每秒的操作次数)仅为该机器理论上应该能够达到的峰值操作的 52%。因此,Feldman和Cerebras着手解决的问题是以一种能够更有效地利用每个计算元件的方式处理越来越庞大的网络,从而带来更好的性能,进而更有效地利用能源。新计算机包括可协同操作的三个部分。一个是该公司含有晶圆级引擎即WSE芯片(有史以来生产的最大芯片)的计算机的更新版。该系统名为CS-2。WSE2和CS-2都已于4月推出。Cerebras Systems AI产品经理Natalia Vassilieva手持该公司的WSE-2,这单单一块芯片的面积几乎与12英寸半导体晶圆的整个表面相当。该芯片于4月首次亮相,是新CS-2机器的核心部件,新CS-2机器是该公司专用AI计算机的第二个版本。本周推出的新元件是一款名为MemoryX的机架式设备,它含有2.4 PB的DRAM和 NAND 闪存,用于存储神经网络的所有权重。第三个设备是所谓的光纤交换机,负责将CS-2连接到MemoryX,名为SwarmX。该交换机可以将多达192台CS-2机器连接到MemoryX,构成可针对单一大型神经网络协同工作的集群。大型问题的并行处理通常有两种:数据并行或模型并行。迄今为止,Cerebras充分利用了模型并行处理,即神经网络层分布在大型芯片的不同部分,以便各层及其权重可以并行运行。Cerebras软件自动决定如何将各层分配到芯片区域,一些层可以获得比其他层更多的芯片区域。神经权重即参数是矩阵,通常由每个权重四个字节来表示,因此无论权重总数是多少,权重存储基本上是四的倍数。对于拥有1750亿个参数的GPT-3而言,整个神经网络的总面积将是700 GB。单个CS-1可以保存中小型网络的所有参数或庞大模型(比如GPT-3)的所有某个层,由于庞大的片上SRAM:18 GB,无需将任务的部分工作内存拷贝到外部存储器。Cerebras CS 1 3 Stack In Rack
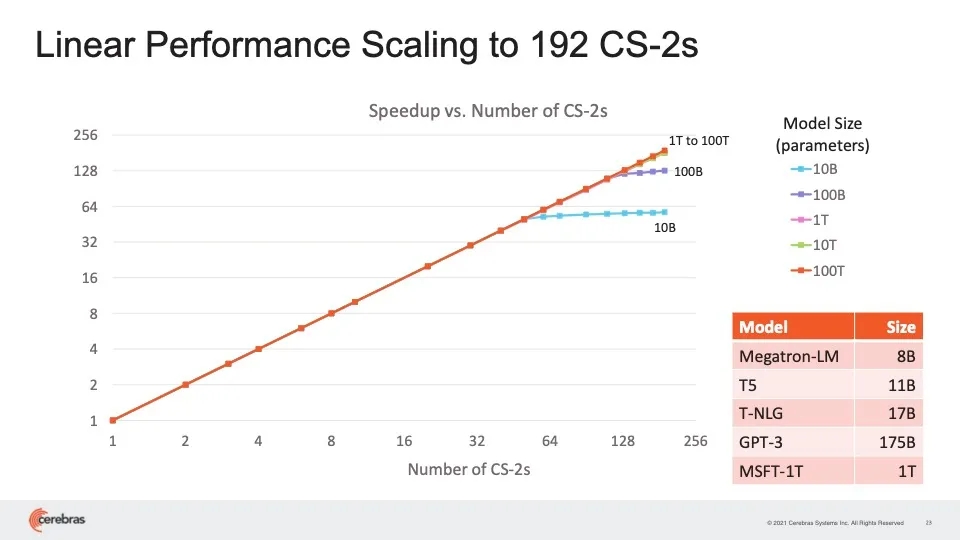
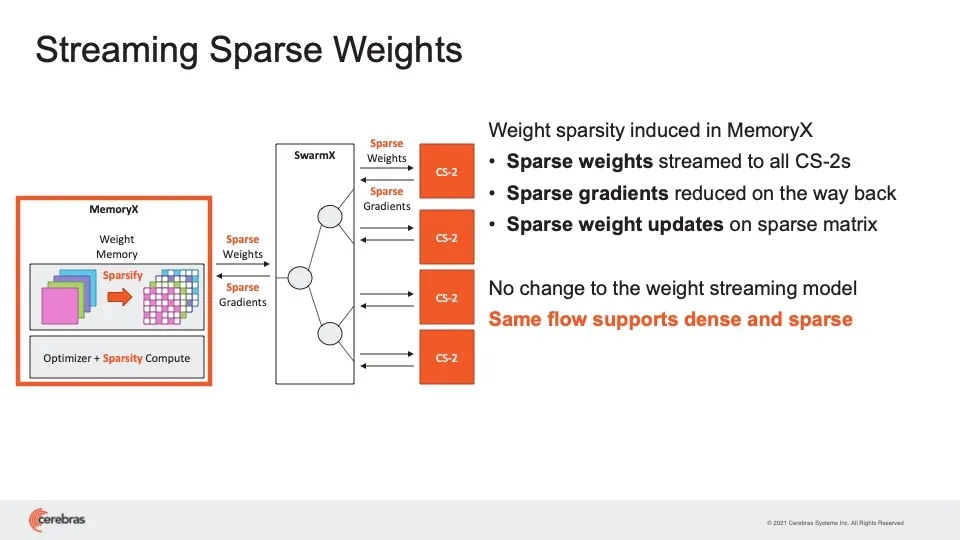
Feldman谈到单个权重矩阵的维度时说:“GPT-3中最大的层大约是12000 x 48000个元素。这可以轻松放在单个 WSE-2上来处理。”Cerebras表示,在新的WSE2芯片中,SRAM内存增加到40 GB,单个CS-2机器就能保存用于120万亿参数神经网络的某一层的所有参数。他特别指出:“我们在Hot Chips大会上展示 48000 x 48000 的矩阵乘法,两倍于GPT-3。”在流式方法中与MemoryX结合使用时,单个CS-2可以处理所有模型权重,因为它们一次一层地流式传输到机器。该公司喜欢将该“大脑级计算”比喻成人类大脑中的100万亿个神经突触。这里的120万亿参数神经网络是由Cerebras内部开发的用于测试用途的合成神经网络,而不是已发布的神经网络。虽然CS-2可以在一台机器中保存所有这些层参数,但Cerebras现在表示可以使用MemoryX来实现数据并行处理。数据并行处理与模型并行处理相反,就在于每台机器都有相同的权重集,但要处理的数据切片不同。为了实现数据并行处理,Cerebras将所有权重保存在MemoryX中,然后有所选择地将这些权重传输给CS-2,CS-2只存储单个数据切片。每个CS-2收到流式权重后,将这些权重应用于输入数据,然后通过激活函数传递结果,激活函数是一种同样存储在芯片上的过滤器,负责检查加权输入以查看是否达到阈值。这一切的最终结果是梯度(即对权重进行的小幅调整),然后梯度发回到MemoryX设备,用于更新权重的主列表。SwarmX处理MemoryX和 CS-2 之间的所有来回传输,但它也处理更多的任务。Feldman解释:“SwarmX既可以处理通信,又可以处理计算。SwarmX交换机结合了梯度(名为消减),这意味着它执行类似求平均值的操作。”Feldman表示,结果是CS-2的利用率与竞争对手相比要高得多,即使在如今的生产级神经网络(比如GPT-3)上也是如此。Feldman说:“别人的利用率在10%或20%之间,而我们在最大网络上的利用率在70%到80%之间——这是闻所未闻的。”添加系统提供了他所谓的“性能线性扩展”,这意味着如果添加16个系统,训练神经网络的速度将随之提高16倍。因此,“今天,每个CS2可取代数百个GPU,而我们现在可以用集群方法取代数千个GPU”,他如是说。Cerebras声称集群机器可实现线性扩展,这意味着每增加一定数量的机器,训练网络的速度会有相应倍数的提高。Cerebras表示,并行处理带来了一个额外的好处,那就是所谓的稀疏性(sparsity)。一开始,Cerebras就认为英伟达GPU的效率非常低,因为它们缺少内存。GPU离不开售价昂贵的主内存DRAM,以便可以成批获取数据。但这意味着GPU可能会对毫无价值的数据进行操作,这是一种浪费。这还意味着在等待每批数据被处理时,权重不会同样频繁地更新。由于WSE拥有大量的片上SRAM,它能够提取单个数据样本,即每次提取一批,并在芯片上并行处理许多这样的单个样本。而对于每个单个样本,同样可以借助高速存储器处理某些权重,有选择且频繁地更新它们。该公司在正式研究论文和AI产品经理Natalia Vassilieva撰写的博文中认为,稀疏性带来了种种好处。它便于更高效地使用内存,并允许动态并行处理,这意味着反向传播(通过神经权重的反向传递)可以压缩成一条有效的管道,进一步提高并行化,并加快训练。这个想法在业界似乎受到越来越大的关注。需要改用集群系统时,Cerebras再次提出了稀疏方法。只需要将一些权重从MemoryX流式传输到每个CS-2,而且只需要将一些梯度发回到MemoryX。换句话说,Cerebras声称由计算机、交换机和内存存储组成的系统区域网络其行为类似于在单个WSE芯片上进行的稀疏计算的大型版本。结合流式方法,CS-2中的稀疏性以及MemoryX和SwarmX拥有一种灵活动态的部件,该公司认为这是其他机器无法比拟的。Feldman说:“每一层可以有不同的稀疏掩码,我们可以为每个轮次(epoch)提供不同的稀疏度;在训练过程中,我们可以改变稀疏度,包括可以充分利用训练过程中所学到知识的稀疏度,名为动态稀疏性,而别人做不到这点。”Feldman补充道,为数据并行处理添加稀疏性,可以将训练大型网络的时间缩短一个数量级。Cerebras提倡大量而灵活地利用名为稀疏性的技术,带来额外的性能优势。当然,更多CS-2机器以及新设备的推销之道将取决于市场是否准备好迎接数万亿或数十万亿权重的神经网络。CS-2及其他部件预计将在今年第四季度出货,因此几个月后即可见分晓。现有客户似乎很感兴趣。美国能源部九大超级计算中心之一的阿尔贡国立实验室一开始就是CS-1系统的用户。虽然这家实验室尚未使用CS-2或其他部件,但研究人员对此充满热情。阿尔贡国立实验室的副主任Rick Stevens在一份准备好的声明中说:“我们在过去几年已看到,对于NLP [自然语言处理]模型而言,结果准确性直接与参数成正比——参数越多,结果就越准确。”Stevens说:“Cerebras的发明将使参数容量增加100倍,这很可能彻底改变业界。我们将首次能够探索大脑级别的模型,为研究和洞察力开辟广阔的新途径。”被问及利用这种计算能力的时机是否成熟时,Feldman说:“没有人在1月份将无酵饼放在货架上”,这种传统的无酵面包只在春天的逾越节前夕正好有人需要时才储备。Feldman表示,AI机器大规模集群的时代已到来。他说:“这不是1月份的无酵饼。”