GPU 构成和工作原理 - 简介
来源:术道经纬 发布时间:2023-07-07 15:59:27 阅读量:1370
金刚钻
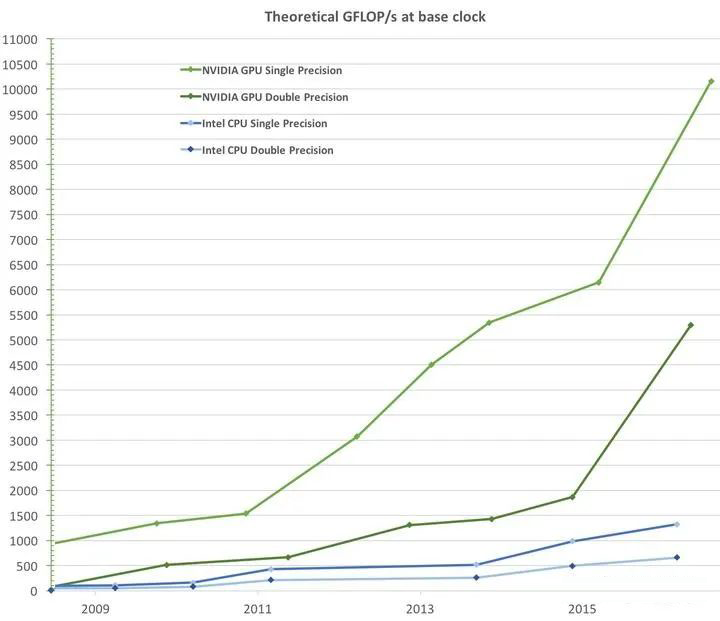
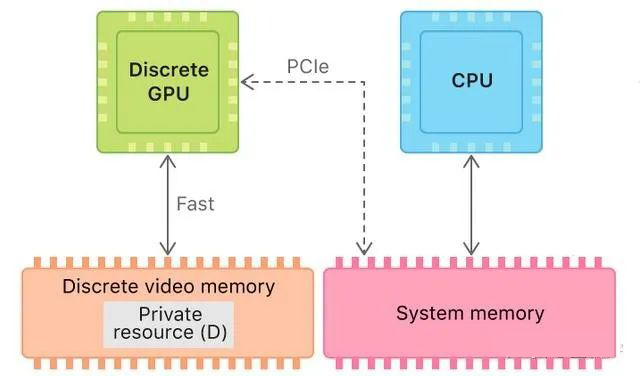
GPU 传统上是用于 graphic 的,但由于其适合并行计算的构造,近几年被越来越多地运用到深度学习和人工智能领域,刮起了一阵猪都能飞的风。尤其是最近国外 AIGC 的技术突破,让 GPU 再次成为一个关注的焦点。 所谓“适合并行计算”,应该是相对传统的 CPU 而言的。要论单个计算单元的能力,CPU 的 ALU(算术逻辑)和 FPU(浮点运算)是要强于 GPU 的: SM's 4-byte registers hold just a single float, whereas the vector registers in an Intel AVX-512 core hold 16 floats.
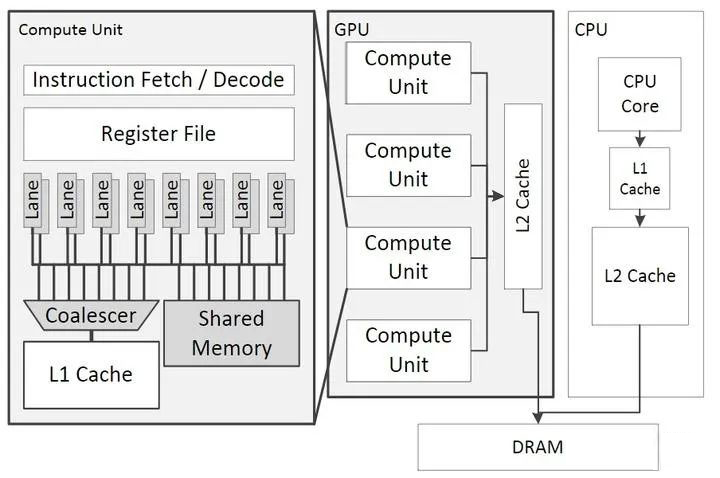
但论数量,CPU 就得自叹不如了。以 Nvidia 为例,其 GPU 由 SM (Streaming Multiprocessor) 构成(AMD 使用的术语是和 OpenCL 标准一致的 CU,即 Compute Unit,以下将混用这两个词),而一个 SM/CU 可运行成百上千的 thread(这个 thread 不同于 GPU 的 thread)。
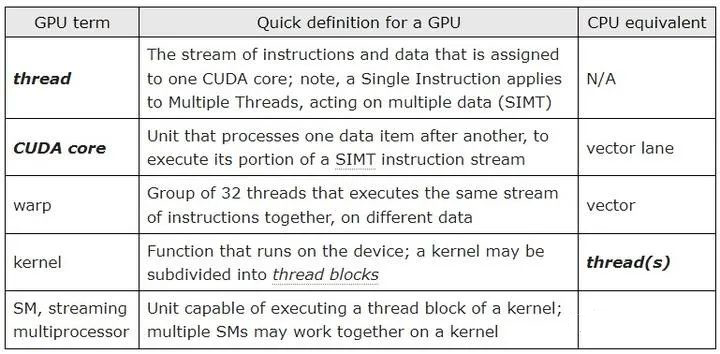
因此也就需要大量保存这些 thread 状态信息的寄存器。以 Nvidia 的 Tesla V100 为例,一个 register file 含有 65536 个 registers。
瓷器活
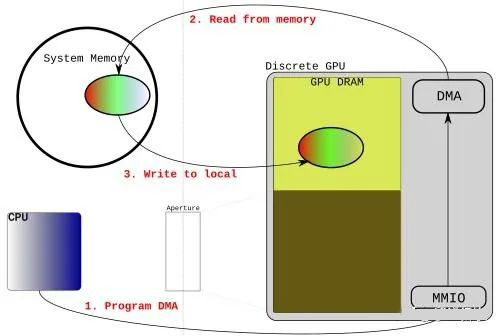
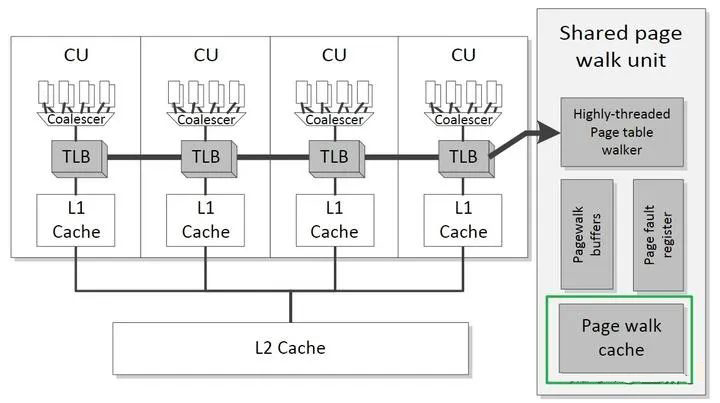
此外,CPU 还可能发送一些 command,来控制 GPU 上 IP 的运行。
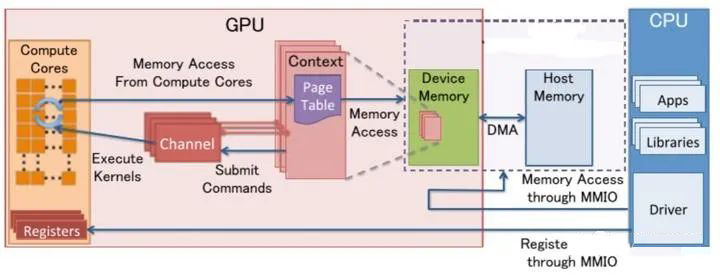
具体的过程是:CPU 侧 userspace 的程序(比如 CUDA),经过专有的编译器,形成一些 command queue,借助 kernel driver 创建的通道,发送到 GPU 侧。command 被 GPU 上的程序处理完后,会将结果返回给 CPU。
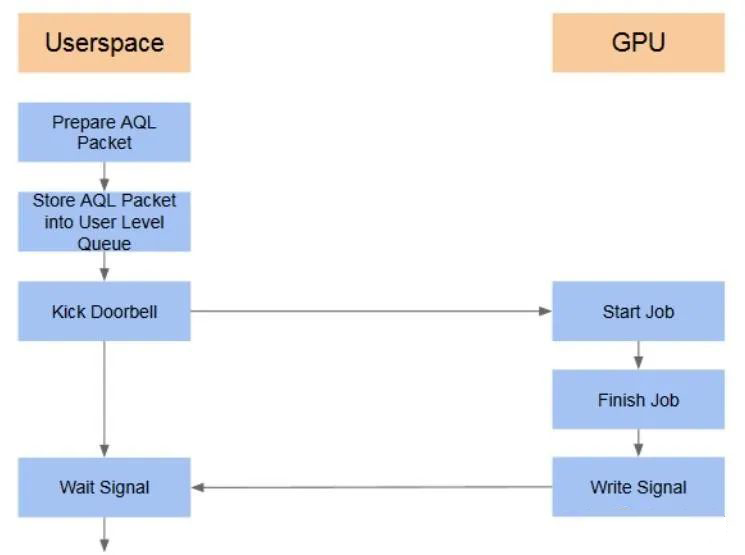
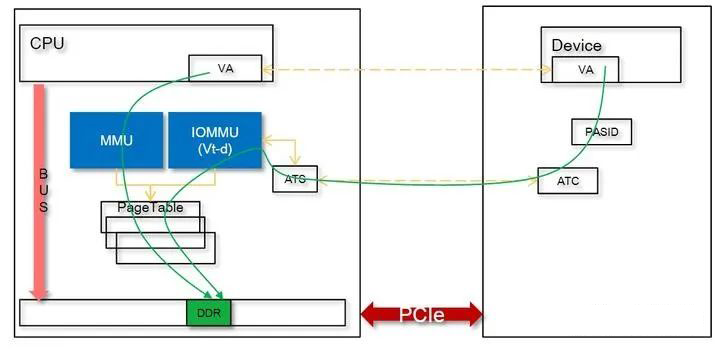
在此过程中,CPU 程序使用的是 CPU VA,GPU 程序使用的是 GPU VA (IOVA),如果两者能保持一致(pointer is pointer),将带来编程上的方便,这叫做 SVA (Share Virtual Address)。
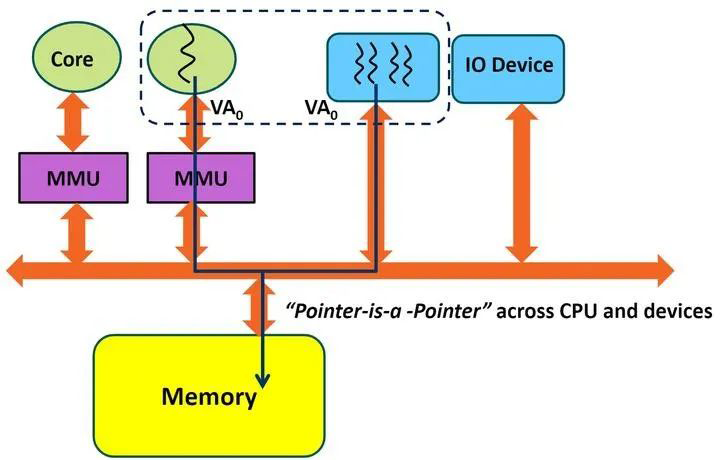
CPU 寻址物理内存使用 MMU,而 GPU 使用系统的 IOMMU 或自己的 GpuMmu,在 SVA 框架下,当共享一段系统内存时,需要 MMU 和 IOMMU 访问的页表项一致。