GPU 虚拟化 [二]
来源:术道经纬 发布时间:2023-07-13 11:27:55 阅读量:962
硬件 - 空分
上文介绍的基于 SR-IOV 硬件虚拟化技术的 GPU,VF 的数量比较固定,且每个 VF 获得的资源是均分的、定额的。将这些 VF 透传给虚拟机后,由于各个虚机的 workload 不同,就可能出现某些 VF 的资源不够用,而另一些 VF 的资源用不完的情况。 饱汉不知饿汉饥,绝对的平均虽然简单,但对资源的利用并不充分。 作为业界一哥的 Nvidia【注-1】,自 2020 年的 Ampere 微架构(比如 A100)开始支持一种叫做 MIG (Multi Instance GPU) 的技术,可使 GPU 的综合利用率更加饱和。毕竟现在高端 GPU 老贵了不是,据 Nvidia 官网报价, A100 售价 1 万美元/块(北上深一平米的价格),H100 售价 3.6 万美元/块(北上深的豪宅一平米的价格),必须物尽其用啊。 Multi-Instance,那一个 instance 具体是什么呢? 一颗 Discrete GPU 的硬件资源主要包括两类:计算单元和内部存储(video memory)。如果对它们分片,那么就形成了 compute slice 和 memory slice(每个 memory slice 有独立的 memory controller 和 cache,不损失访问带宽)。 然后我可以根据 workload 的需要,将这些 slices 进行一定的组合,就形成了多个 instance(vGPU):
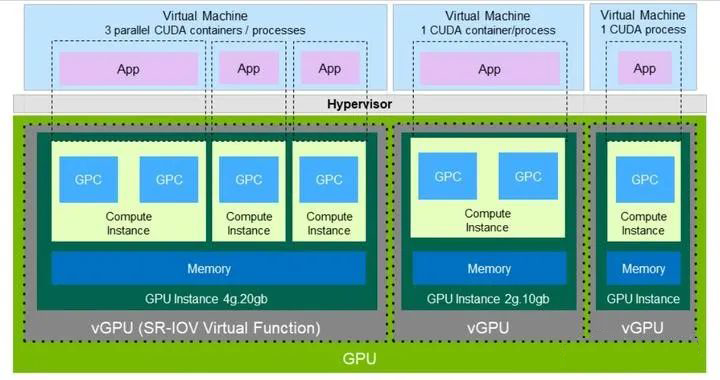
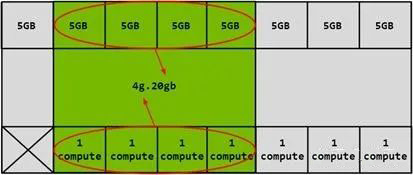
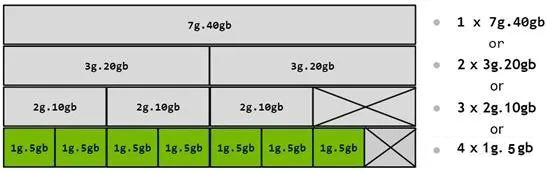
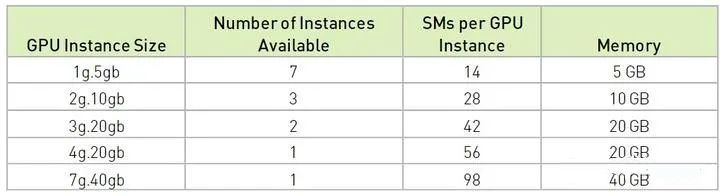
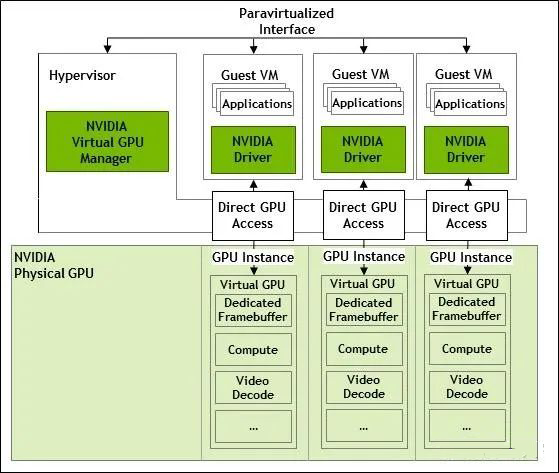
软件 - 时分
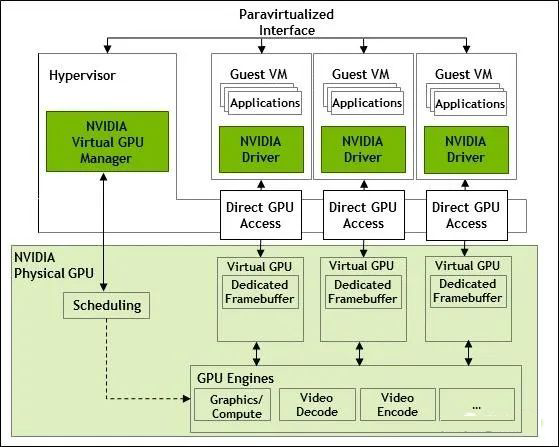
小结

上一篇:GPU 虚拟化 [一]
下一篇:GPU巨头,拼什么?