新的 MLPerf 推理网络部分展现 NVIDIA InfiniBand 网络和 GPUDirect RDMA 的强大能力
来源:NVIDIA英伟达 发布时间:2023-08-21 11:44:00 阅读量:585

在 MLPerf Inference v3.0 中,NVIDIA 首次将网络纳入了 MLPerf 的评测项目,成为了 MLPerf 推理数据中心套件的一部分。网络评测部分旨在模拟在真实的数据中心中,网络软、硬件对于端到端推理性能的影响。
在网络评测中,有两类节点:前端节点生成查询,这些查询通过业界标准的网络(如以太网或 InfiniBand 网络)发送到加速节点,由加速器节点进行处理和执行推理。
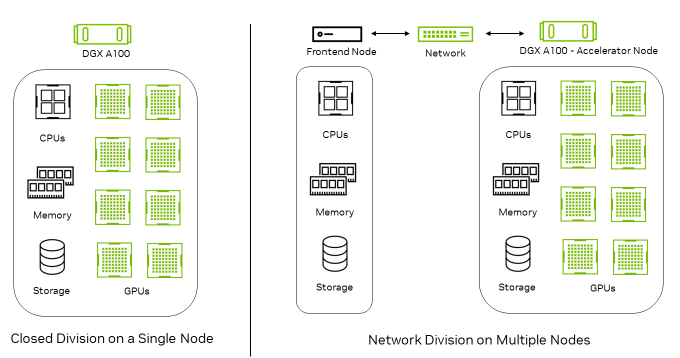
图 1:单节点封闭测试环境与多节点网络测试环境
图 1 显示了在单个节点上运行的封闭测试环境,以及在网络测试环境中通过前端节点生成查询,然后传输到加速器节点上进行推理的工作流程。
在网络测试场景中,加速器节点包含了推理加速器以及所有网络组件,包括网卡(NIC)、网络交换机和完整的网络体系。因此,网络评测旨在测试加速器节点和网络的性能,因为前端节点在基准测试中的作用有限,可以排除它们对测试的影响。
MLPerf 推理 v3.0 网络评测中的
NVIDIA 网络性能表现
在 MLPerf 推理 v3.0 中,NVIDIA 提交了在 ResNet-50 和 BERT 两种场景下的网络性能结果,从 NVIDIA 提交的性能结果来看,凭借 NVIDIA ConnectX-6 InfiniBand 智能网卡和 GPUDirect RDMA 技术提供的超高网络带宽和极低延迟,ResNet-50 在网络环境中达到了 100% 的单节点性能。

表 1:ResNet-50 和 BERT 上网络评测性能和单机封闭测试性能的比较,有限带宽实现了理想性能
NVIDIA 平台在 BERT 工作负载方面也表现出了出色的性能,和单机封闭测试结果性能仅有轻微的差异,这主要是由于主机端的一些开销而导致。
在 NVIDIA 网络评测中用到的关键技术
大量的全栈技术使 NVIDIA 网络评测中的强大性能得以实现:
NVIDIA TensorRT 优化推理引擎。
InfiniBand RDMA 网络,为张量通信提供低延迟和高带宽,基于 Mellanox OFED 软件堆栈中的 IBV verbs 实现。
通过以太网 TCP Socket 进行配置交换、运行状态同步和心跳监控。
利用 CPU、GPU 和 NIC 资源获得最佳性能时 NUMA-Aware。
网络评测部分实施细节
以下是 MLPerf 推理中网络评测部分的实现细节:
采用高吞吐量、低延迟的 InfiniBand 网络进行通信 网络评测部分推理流程 性能优化
通过高吞吐量、低延迟的
InfiniBand 网络进行通信
网络评测过程要求提交者通过查询调度库(QDL)从负载生成器获取查询,然后根据提交者设置的方式将查询发送到加速器节点。
在生成输入张量序列的前端节点,QDL 通过测试端(SUT)的 API 对 LoadGen 系统进行抽象,这样用于本地测试的加速器的 MLPerf 推理 LoadGen 就变得可见。
在加速器节点,通过 QDL 与负责推理请求和响应的 LoadGen 直接交互。在 NVIDIA 的 QDL 实现中,我们使用 InfiniBand IBV verbs 和以太网 TCP Socket 实现了无缝数据通信和同步。
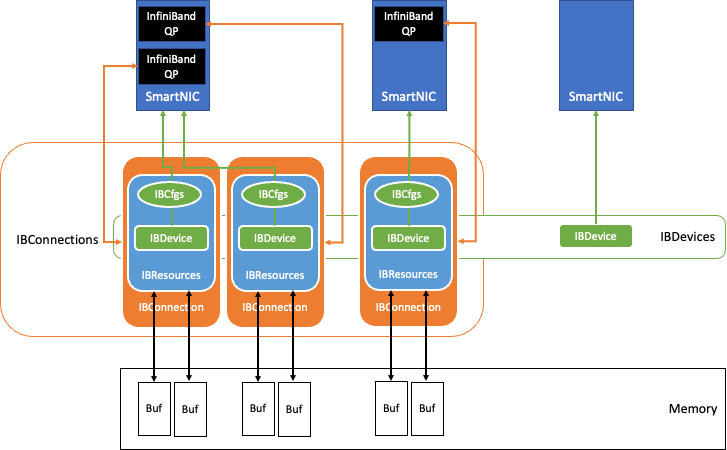
图 2:QDL 内部的 InfiniBand 数据交换组件
图 2 显示了基于 InfiniBand 网络技术的 QDL 中的数据交换组件。

图 3:前端节点和加速器节点之间建立连接的示例
图 3 显示了如何使用该数据交换组件在两个节点之间建立连接。
InfiniBand 网络的队列对(QPs)是节点之间的连接的基础。NVIDIA 采用了无损可靠连接(RC)方式(和 TCP 类似)和传输模式,并利用 InfiniBand HDR 光纤网络来维持高达 200 Gbits/sec 的吞吐量。
基准测试开始时,QDL 在初始化过程中会发现系统中的所有 InfiniBand 网卡,并根据存储在 IBCfgs 中的配置信息,指定网卡作为测试的 IBDevice 实例。在这个测试过程中,用于 RDMA 传输的内存区域被分配、固定和注册为 RDMA 缓冲区,并与相应的的 Handle 一起保存在 IBResources 中。
利用 GPUDirect RDMA 技术,可以将加速器节点的 GPU 显存作为 RDMA 缓冲区,并将 RDMA 缓冲区信息以及相应的保护密钥通过以太网的 TCP Socket 发送给相对应的节点,这样就为 QDL 创建 IBConnection 实例。
由于 QDL 支持 NUMA-Aware,可将最近的 NUMA 主机内存、CPU 和 GPU 映射到每张网卡,每个 NIC 都通过 IBConnection 与对端网卡 NIC 进行通信。
网络评测部分推理流程
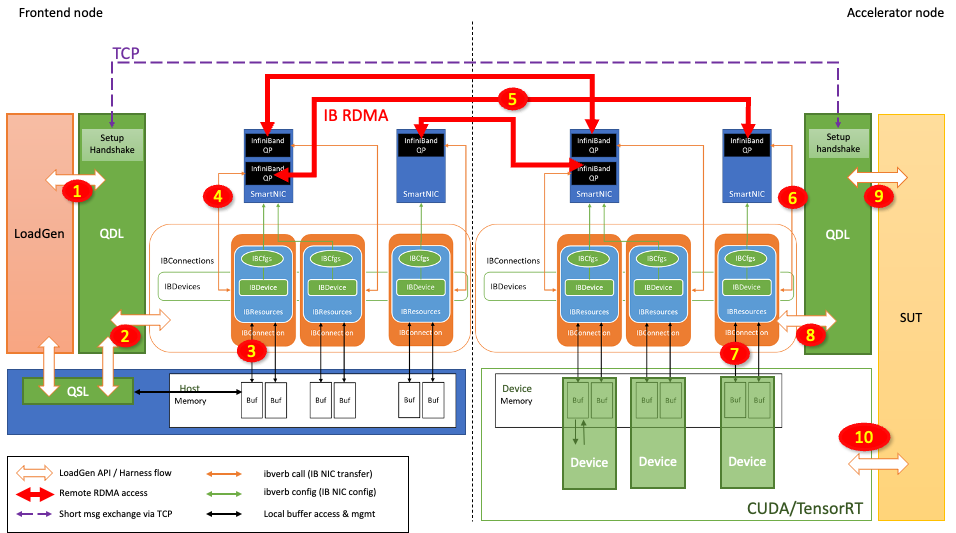
图 4:使用 Direct GPU RDMA 从前端节点到加速器节点的推理请求流
图 4 显示了推理请求是如何从前端节点发送到加速器节点并在加速器节点上被处理的:
LoadGen 生成一个查询(推理请求),其中包含输入张量。
QDL 通过仲裁的方式将该查询重定向到适当的 IBConnection。
查询样本库(QSL)可能已经被注册在 RDMA 缓冲区内。如果没有,则 QDL 将查询复制到 RDMA 缓冲区。
QDL 启动相应的 QP 的 RDMA 传输。
通过网络交换机实现 InfiniBand 网络传输。
查询到达对等方的 QP。
然后通过直接内存访问技术将查询传输到目的地 RDMA 缓冲区。
加速器节点的 QDL 确认 RDMA 传输完成。
QDL 允许加速器节点能够批处理查询,QDL 标记一批查询,发布到加速器节点的某个加速器上去执行。
加速器节点的加速器使用 CUDA 和 TensorRT 执行推理,在 RDMA 缓冲区中生成响应。
当在步骤 10 最终执行推理后,会生成输出张量,并将其置于 RDMA 缓冲区中。然后加速器节点开始以类似的方式但以相反的方向将响应张量传输到前端节点。
性能优化
NVIDIA 使用 InfiniBand RDMA_Write 的方式实现了最短的延迟。要成功地应用 RDMA_Write,发送方必须对于对端的内存缓冲区可见。
前端节点和加速器节点都需要管理缓冲区跟踪器,以确保每个查询和响应都保存在内存中,直到用完为止。例如,ResNet-50 要想达到理想的性能需要每个连接(QP)管理多达 8K 个交易。
NVIDIA 用到了以下一些关键优化。
以下关键优化支持更好的可扩展性:
每个 IBConnection(QP)的交易跟踪器:每个 IBConnection 都有一个独立的交易跟踪器,从而实现无死锁的、关联内交易记账。
每个网卡支持多个 QP:任意数量的 IBConnections 可以在任何网卡上实例化,从而可以轻松地自发支持大量交易。
以下关键优化提高了 InfiniBand 网络的资源效率:
使用 INLINE 的方式传输小消息:通过 INLINE 传输小消息(通常指小于 64 字节)可避免 PCIe 传输,从而显著提高性能和效率。
使用 UNSIGNALLED RDMA Write:由于 UNSIGNALLED 的操作需要在 CQ 队列中等待直到 SIGNALLED 操作发生,再触发到目前为止在同一节点中排队的所有事务的完成处理(批量完成),因此 CQ 维护变得更加高效。
使用 Solicited IB 传输:Unsolicited 的 RDMA 操作可以在远端节点中排队等待,直到 solicited RDMA 操作发生,再触发远端节点中的批量完成。
基于事件的 CQ 管理:避免 CPU 一直忙于等待 CQ,释放 CPU 个周期。
以下关键优化提高了内存系统的效率:
通过 RDMA 传输避免了前端节点内的内存拷贝:发送输入张量时,通过直接将张量存在在 RDMA 注册的内存中来避免主机内存拷贝。
在加速器节点中聚合 CUDA 的 memcpys:通过尽可能多地集中连续内存中的张量,提高 GPU 显存拷贝和 PCIe 传输的效率。
每家的 QP 实现涵盖了能支持的最大完成队列条目数(CQE),以及支持的最大 QP 条目数。扩展每个网卡能支持的 QP 数量,对于降低延迟,同时保持足够的实时交易量以实现最大吞吐量很重要。
如果 CQ 通过轮询的方式在短时间内处理大量事务,会对主机 CPU 造成显著的压力,在这种情况下,采用基于事件的 CQ 管理,以及减少通知的数量会对此非常有帮助。通过尽可能多地聚集连续内存空间中的数据,如果可能,聚集在 RDMA 注册的内存空间,可以最大限度地提高内存访问效率。这对于实现最大性能至关重要。
总结
NVIDIA 平台在其首次提交的网络测试结果中表现出色,充分体现了 NVIDIA 在 MLPerf 推理:数据中心封闭部门评测项目中一贯的领先地位,这些结果归功于许多 NVIDIA 平台的强大功能实现:
NVIDIA A100 Tensor Core GPU
NVIDIA DGX A100
NVIDIA ConnectX-6 InfiniBand 网络
NVIDIA TensorRT
GPUDirect RDMA
这个结果进一步证明了 NVIDIA AI 平台 在行业标准的、业界公认的真实数据中心部署中的高性能和多样性。
在 MLPerf Inference v3.0 中,NVIDIA 首次将网络纳入了 MLPerf 的评测项目,成为了 MLPerf 推理数据中心套件的一部分。网络评测部分旨在模拟在真实的数据中心中,网络软、硬件对于端到端推理性能的影响。
在网络评测中,有两类节点:前端节点生成查询,这些查询通过业界标准的网络(如以太网或 InfiniBand 网络)发送到加速节点,由加速器节点进行处理和执行推理。
图 1:单节点封闭测试环境与多节点网络测试环境
图 1 显示了在单个节点上运行的封闭测试环境,以及在网络测试环境中通过前端节点生成查询,然后传输到加速器节点上进行推理的工作流程。
在网络测试场景中,加速器节点包含了推理加速器以及所有网络组件,包括网卡(NIC)、网络交换机和完整的网络体系。因此,网络评测旨在测试加速器节点和网络的性能,因为前端节点在基准测试中的作用有限,可以排除它们对测试的影响。
MLPerf 推理 v3.0 网络评测中的
NVIDIA 网络性能表现
在 MLPerf 推理 v3.0 中,NVIDIA 提交了在 ResNet-50 和 BERT 两种场景下的网络性能结果,从 NVIDIA 提交的性能结果来看,凭借 NVIDIA ConnectX-6 InfiniBand 智能网卡和 GPUDirect RDMA 技术提供的超高网络带宽和极低延迟,ResNet-50 在网络环境中达到了 100% 的单节点性能。
表 1:ResNet-50 和 BERT 上网络评测性能和单机封闭测试性能的比较,有限带宽实现了理想性能
NVIDIA 平台在 BERT 工作负载方面也表现出了出色的性能,和单机封闭测试结果性能仅有轻微的差异,这主要是由于主机端的一些开销而导致。
在 NVIDIA 网络评测中用到的关键技术
大量的全栈技术使 NVIDIA 网络评测中的强大性能得以实现:
NVIDIA TensorRT 优化推理引擎。
InfiniBand RDMA 网络,为张量通信提供低延迟和高带宽,基于 Mellanox OFED 软件堆栈中的 IBV verbs 实现。
通过以太网 TCP Socket 进行配置交换、运行状态同步和心跳监控。
利用 CPU、GPU 和 NIC 资源获得最佳性能时 NUMA-Aware。
网络评测部分实施细节
采用高吞吐量、低延迟的 InfiniBand 网络进行通信 网络评测部分推理流程 性能优化
通过高吞吐量、低延迟的
InfiniBand 网络进行通信
网络评测过程要求提交者通过查询调度库(QDL)从负载生成器获取查询,然后根据提交者设置的方式将查询发送到加速器节点。
在生成输入张量序列的前端节点,QDL 通过测试端(SUT)的 API 对 LoadGen 系统进行抽象,这样用于本地测试的加速器的 MLPerf 推理 LoadGen 就变得可见。
在加速器节点,通过 QDL 与负责推理请求和响应的 LoadGen 直接交互。在 NVIDIA 的 QDL 实现中,我们使用 InfiniBand IBV verbs 和以太网 TCP Socket 实现了无缝数据通信和同步。
图 2:QDL 内部的 InfiniBand 数据交换组件
图 2 显示了基于 InfiniBand 网络技术的 QDL 中的数据交换组件。
图 3:前端节点和加速器节点之间建立连接的示例
图 3 显示了如何使用该数据交换组件在两个节点之间建立连接。
InfiniBand 网络的队列对(QPs)是节点之间的连接的基础。NVIDIA 采用了无损可靠连接(RC)方式(和 TCP 类似)和传输模式,并利用 InfiniBand HDR 光纤网络来维持高达 200 Gbits/sec 的吞吐量。
基准测试开始时,QDL 在初始化过程中会发现系统中的所有 InfiniBand 网卡,并根据存储在 IBCfgs 中的配置信息,指定网卡作为测试的 IBDevice 实例。在这个测试过程中,用于 RDMA 传输的内存区域被分配、固定和注册为 RDMA 缓冲区,并与相应的的 Handle 一起保存在 IBResources 中。
利用 GPUDirect RDMA 技术,可以将加速器节点的 GPU 显存作为 RDMA 缓冲区,并将 RDMA 缓冲区信息以及相应的保护密钥通过以太网的 TCP Socket 发送给相对应的节点,这样就为 QDL 创建 IBConnection 实例。
由于 QDL 支持 NUMA-Aware,可将最近的 NUMA 主机内存、CPU 和 GPU 映射到每张网卡,每个 NIC 都通过 IBConnection 与对端网卡 NIC 进行通信。
网络评测部分推理流程
图 4:使用 Direct GPU RDMA 从前端节点到加速器节点的推理请求流
图 4 显示了推理请求是如何从前端节点发送到加速器节点并在加速器节点上被处理的:
LoadGen 生成一个查询(推理请求),其中包含输入张量。
QDL 通过仲裁的方式将该查询重定向到适当的 IBConnection。
查询样本库(QSL)可能已经被注册在 RDMA 缓冲区内。如果没有,则 QDL 将查询复制到 RDMA 缓冲区。
QDL 启动相应的 QP 的 RDMA 传输。
通过网络交换机实现 InfiniBand 网络传输。
查询到达对等方的 QP。
然后通过直接内存访问技术将查询传输到目的地 RDMA 缓冲区。
加速器节点的 QDL 确认 RDMA 传输完成。
QDL 允许加速器节点能够批处理查询,QDL 标记一批查询,发布到加速器节点的某个加速器上去执行。
加速器节点的加速器使用 CUDA 和 TensorRT 执行推理,在 RDMA 缓冲区中生成响应。
当在步骤 10 最终执行推理后,会生成输出张量,并将其置于 RDMA 缓冲区中。然后加速器节点开始以类似的方式但以相反的方向将响应张量传输到前端节点。
性能优化
NVIDIA 使用 InfiniBand RDMA_Write 的方式实现了最短的延迟。要成功地应用 RDMA_Write,发送方必须对于对端的内存缓冲区可见。
前端节点和加速器节点都需要管理缓冲区跟踪器,以确保每个查询和响应都保存在内存中,直到用完为止。例如,ResNet-50 要想达到理想的性能需要每个连接(QP)管理多达 8K 个交易。
NVIDIA 用到了以下一些关键优化。
以下关键优化支持更好的可扩展性:
每个 IBConnection(QP)的交易跟踪器:每个 IBConnection 都有一个独立的交易跟踪器,从而实现无死锁的、关联内交易记账。
每个网卡支持多个 QP:任意数量的 IBConnections 可以在任何网卡上实例化,从而可以轻松地自发支持大量交易。
以下关键优化提高了 InfiniBand 网络的资源效率:
使用 INLINE 的方式传输小消息:通过 INLINE 传输小消息(通常指小于 64 字节)可避免 PCIe 传输,从而显著提高性能和效率。
使用 UNSIGNALLED RDMA Write:由于 UNSIGNALLED 的操作需要在 CQ 队列中等待直到 SIGNALLED 操作发生,再触发到目前为止在同一节点中排队的所有事务的完成处理(批量完成),因此 CQ 维护变得更加高效。
使用 Solicited IB 传输:Unsolicited 的 RDMA 操作可以在远端节点中排队等待,直到 solicited RDMA 操作发生,再触发远端节点中的批量完成。
基于事件的 CQ 管理:避免 CPU 一直忙于等待 CQ,释放 CPU 个周期。
以下关键优化提高了内存系统的效率:
通过 RDMA 传输避免了前端节点内的内存拷贝:发送输入张量时,通过直接将张量存在在 RDMA 注册的内存中来避免主机内存拷贝。
在加速器节点中聚合 CUDA 的 memcpys:通过尽可能多地集中连续内存中的张量,提高 GPU 显存拷贝和 PCIe 传输的效率。
每家的 QP 实现涵盖了能支持的最大完成队列条目数(CQE),以及支持的最大 QP 条目数。扩展每个网卡能支持的 QP 数量,对于降低延迟,同时保持足够的实时交易量以实现最大吞吐量很重要。
如果 CQ 通过轮询的方式在短时间内处理大量事务,会对主机 CPU 造成显著的压力,在这种情况下,采用基于事件的 CQ 管理,以及减少通知的数量会对此非常有帮助。通过尽可能多地聚集连续内存空间中的数据,如果可能,聚集在 RDMA 注册的内存空间,可以最大限度地提高内存访问效率。这对于实现最大性能至关重要。
总结
NVIDIA 平台在其首次提交的网络测试结果中表现出色,充分体现了 NVIDIA 在 MLPerf 推理:数据中心封闭部门评测项目中一贯的领先地位,这些结果归功于许多 NVIDIA 平台的强大功能实现:
NVIDIA A100 Tensor Core GPU
NVIDIA DGX A100
NVIDIA ConnectX-6 InfiniBand 网络
NVIDIA TensorRT
GPUDirect RDMA
这个结果进一步证明了 NVIDIA AI 平台 在行业标准的、业界公认的真实数据中心部署中的高性能和多样性。