近日,Intel正式公布了2023至2025年的Xeon处理器产品路线图。根据此计划,未来几年将会推出Emerald Rapids、Granite Rapids和Sierra Forest以及Clearwater Forest等P核心/E核心系列产品。Intel正式公布了2023至2025年的Xeon处理器产品路线图。根据此计划,未来几年将会推出Emerald Rapids、Granite Rapids和Sierra Forest以及Clearwater Forest等P核心/E核心系列产品。段落大纲
Intel 已将其下一代 Xeon 数据中心 CPU 产品线划分为两个类别:P-Core 和 E-Core。P-Core 产品将是我们多年来所熟悉的标准 Xeon 产品。而E-Core产品将利用更节能的架构,预计明年将推出第一款产品,名为Sierra Forest。

2023 年 Intel 第五代 Xeon:Emerald Rapids

Emerald Rapids将成为2023年的主打产品,预期将于今年第四季登场,基于Intel 7的制程技术。这款新一代的 Xeon 处理器将提供更高的性能和能效,满足高性能计算(HPC)、人工智能(AI)和数据中心等领域的需求。
Emerald Rapids-SP 产品线的其他特点包括在相同功耗范围内专注于提高性能 / 瓦特比,并在每代产品中提高核心密度。这些芯片将与现有的第四代Eagle Stream平台完全兼容,使得从上一代产品转移变得容易。预计Emerald Rapids将使用Reaptor Cove核心架构,该架构是对Golden Cove核心的优化版本,将在Golden Cove核心的基础上提高5-10%的IPC性能。它还将拥有最多 64C128T 配置,这在核心数上略高于 Sapphire Rapids 芯片所拥有的 56C112T。Intel Emerald Rapids-SP (64 核 SKU):320MB L3 + 128MB L2 = 448MB
AMD EPYC Genoa (64 核 SKU):384MB L3 + 96MB L2 = 480MB
Intel Sapphire Rapids-SP (60 核 SKU):112.5MB L3 + 120MB L2 = 232.5MB
Emerald Rapids-SP Xeon CPU的核心数将达到64个,并适用于1S / 2S服务器配置。至于 4S – 8S 平台,则需要等到下一代 Granite Rapids-SP Xeon 才能升级。然而,值得一提的是,Emerald Rapids-SP Xeon CPU 预计在 L3 快取方面将有巨大的提升。据报道,Emerald Rapids-SP CPU将配备高达 320MB 的 L3 快取。这比最高端的 Sapphire Rapids-SP Xeon 8490H 上的 112.5MB L3 快取高出 2.84 倍。2024 年:Granite Rapids 和 Sierra Forest

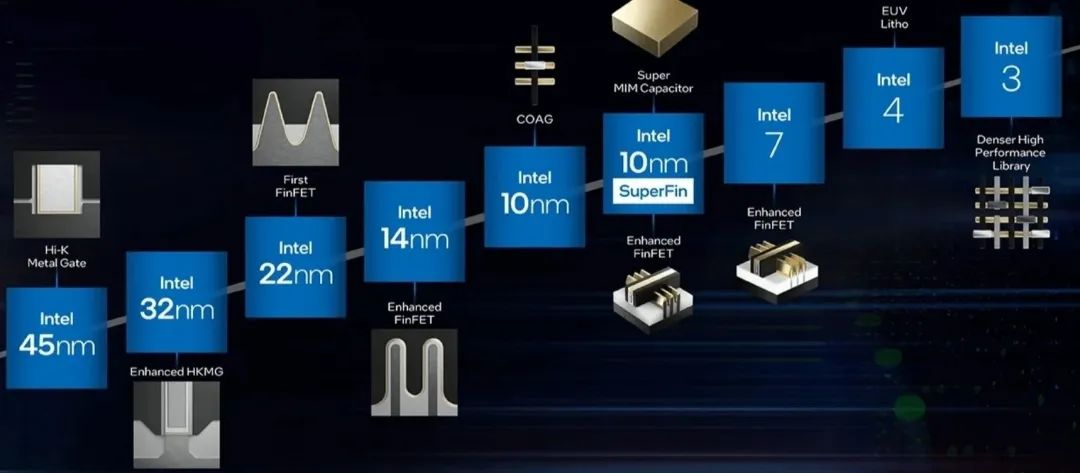
2024年,Intel将推出基于更先进制程技术的Granite Rapids和Sierra Forest产品,采Intel3制程、Redwood Cove核心架构。
在 Mountain Stream 和 Birch Stream 平台上提供支持的 Granite Rapids-SP Xeon CPU 将进一步提高核心密度、内存和 I/O 创新,例如支持 DDR5-8800 MCR 内存,新的内存将提供 83% 的峰值带宽,并为平台提供高达 1.5 TB/s 的带宽。Intel 甚至展示了一个早期 Granite Rapids-SP 芯片在双插槽平台(2S)上运行 DDR5-8000 MT/s 内存的演示。推出Granite Rapids-SP Xeon CPU的同时,Intel还将推出其首款代号为Sierra Forest的E-Core产品,该产品已经取得了优秀的硅片健康状态,并预计于2024年上半年推出。该CPU将搭载高达144个基于Intel 3制程节点的核心,并推出一个新类别的Xeon芯片,专为云端优化工作负载而设计。 在这个阶段,Intel想要与AMD的所有产品展开竞争。标准的可扩展家族与主要的EPYC对手竞争,而Sierra Forest将与一系列针对计算优化的EPYC产品竞争。拥有144个核心的Sierra Forest将与AMD的EPYC Bergamo 128核心CPU竞争,后者在同一个云数据中心领域中使用性能调校过的Zen 4C架构。
在这个阶段,Intel想要与AMD的所有产品展开竞争。标准的可扩展家族与主要的EPYC对手竞争,而Sierra Forest将与一系列针对计算优化的EPYC产品竞争。拥有144个核心的Sierra Forest将与AMD的EPYC Bergamo 128核心CPU竞争,后者在同一个云数据中心领域中使用性能调校过的Zen 4C架构。2025 年:Clearwater Forest
这些芯片将被计划于2025年推出的第二代E-Core Xeon产品家族取代,名为Clearwater Forest,该产品将使用Intel 18A制程节点,并提供更高的核心数量。Intel 18A制程节点将对RibbonFET架构进行优化,以实现晶体管和芯片性能的另一个重大突破。
除此之外,该公司还更新了其未来GPU、专用AI和FPGA的产品路线图。GPU 产品线将推出代号为 Melville Sound 的新一代数据中心 GPU Flex 系列,公司还将推出代号为 Falcon Shores 的未来加速器。Falcon Shores最近取代了Rialto Bridge,并且在第一代产品中只具有GPU核心,随后的一代将以类似于AMD的InstinctMI300加速器的片状方式结合CPU和GPU核心。
同时还提及了采用全新架构的下一代 Habana Gaudi 加速器以及 eASIC 和 AGILEX 系列下的下一代 FPGA。Intel 的未来路线图和产品阵容看起来充满了大量芯片,但主要问题仍然是芯片巨头能否按时实现路线图里程碑,还是会面临与过去几代产品阵容相似的延迟。
未来几年的 Xeon 处理器路线图显示了该公司对持续创新和改进产品性能的承诺。从 Emeral Rapids 到 Granite Rapids 暨 Sierra Forest,再到 Clearwater Forest,这些产品将使 Intel 保持在高性能计算、人工智能和数据中心等领域的竞争力。同时,这些新型处理器将提供更高的性能、更好的能效和更强大的扩展性,以满足未来各种应用场景的需求。