77% 的 Linux 运维都不懂的内核问题,这篇全告诉你了
来源:高效运维 发布时间:2023-03-06 16:01:52 阅读量:1057
前言
【OOM - Out of Memory】内存溢出
内存溢出的解决办法:
1、等比例缩小图片
2、对图片采用软引用,及时进行 recycle( ) 操作。
3、使用加载图片框架处理图片,如专业处理图片的 ImageLoader 图片加载框架,还有XUtils 的 BitMapUtils 来处理。
下面主要从以下方面介绍 Linux 内存管理:
进程的内存申请与分配;
内存耗尽之后 OOM;
申请的内存都在哪?
系统回收内存;
1、进程的内存申请与分配
之前有篇文章介绍 hello world 程序是如何载入内存以及是如何申请内存的,我在这,再次说明下:同样,还是先给出进程的地址空间,我觉得对于任何开发人员这张图是必须记住的,还有一张就是操作 disk ,memory 以及 cpu cache 的时间图。
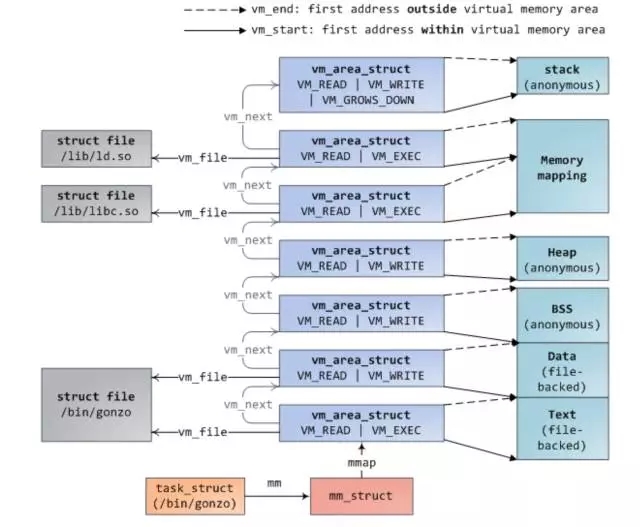
当我们在终端启动一个程序时,终端进程调用 exec 函数将可执行文件载入内存,此时代码段,数据段,bbs 段,stack 段都通过 mmap 函数映射到内存空间,堆则要根据是否有在堆上申请内存来决定是否映射。
exec 执行之后,此时并未真正开始执行进程,而是将 cpu 控制权交给了动态链接库装载器,由它来将该进程需要的动态链接库装载进内存。之后才开始进程的执行,这个过程可以通过 strace 命令跟踪进程调用的系统函数来分析。

这是我上篇博客认识 pipe 中的程序,从这个输出过程,可以看出和我上述描述的一致。
当第一次调用 malloc 申请内存时,通过系统调用 brk 嵌入到内核,首先会进行一次判断,是否有关于堆的 vma,如果没有,则通过 mmap 匿名映射一块内存给堆,并建立 vma 结构,挂到 mm_struct 描述符上的红黑树和链表上。
然后回到用户态,通过内存分配器(ptmaloc,tcmalloc,jemalloc)算法将分配到的内存进行管理,返回给用户所需要的内存。
如果用户态申请大内存时,是直接调用 mmap 分配内存,此时返回给用户态的内存还是虚拟内存,直到第一次访问返回的内存时,才真正进行内存的分配。
其实通过 brk 返回的也是虚拟内存,但是经过内存分配器进行切割分配之后(切割就必须访问内存),全都分配到了物理内存
2、内存耗尽之后OOM
在实习期间,有一台测试机上的 mysql 实例经常被 oom 杀死,OOM(out of memory)即为系统在内存耗尽时的自我拯救措施,他会选择一个进程,将其杀死,释放出内存,很明显,哪个进程占用的内存最多,即最可能被杀死,但事实是这样的吗?

OOM 关键文件 oom_kill.c,里面介绍了当内存不够时,系统如何选择最应该被杀死的进程,选择因素有挺多的,除了进程占用的内存外,还有进程运行的时间,进程的优先级,是否为 root 用户进程,子进程个数和占用内存以及用户控制参数 oom_adj 都相关。
当产生 oom 之后,函数 select_bad_process 会遍历所有进程,通过之前提到的那些因素,每个进程都会得到一个 oom_score 分数,分数最高,则被选为杀死的进程。
我们可以通过设置 /proc/<pid>/oom_adj 分数来干预系统选择杀死的进程。
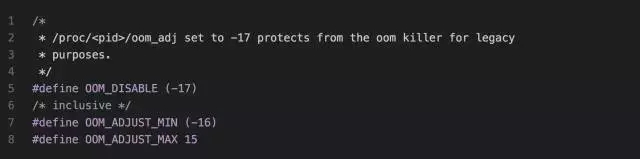
这是内核关于这个oom_adj调整值的定义,最大可以调整为15,最小为-16,如果为-17,则该进程就像买了vip会员一样,不会被系统驱逐杀死了,因此,如果在一台机器上有跑很多服务器,且你不希望自己的服务被杀死的话,就可以设置自己服务的 oom_adj 为-17。
当然,说到这,就必须提到另一个参数 /proc/sys/vm/overcommit_memory,man proc 说明如下:

意思就是当 overcommit_memory 为0时,则为启发式oom,即当申请的虚拟内存不是很夸张的大于物理内存,则系统允许申请,但是当进程申请的虚拟内存很夸张的大于物理内存,则就会产生 OOM。
例如只有8g的物理内存,然后 redis 虚拟内存占用了24G,物理内存占用3g,如果这时执行 bgsave,子进程和父进程共享物理内存,但是虚拟内存是自己的,即子进程会申请24g的虚拟内存,这很夸张大于物理内存,就会产生一次OOM。
当 overcommit_memory 为1时,则永远都允许 overmemory 内存申请,即不管你多大的虚拟内存申请都允许,但是当系统内存耗尽时,这时就会产生oom,即上述的redis例子,在 overcommit_memory=1 时,是不会产生oom 的,因为物理内存足够。
当 overcommit_memory 为2时,永远都不能超出某个限定额的内存申请,这个限定额为 swap+RAM* 系数(/proc/sys/vm/overcmmit_ratio,默认50%,可以自己调整),如果这么多资源已经用光,那么后面任何尝试申请内存的行为都会返回错误,这通常意味着此时没法运行任何新程序
以上就是 OOM 的内容,了解原理,以及如何根据自己的应用,合理的设置OOM。
3、系统申请的内存都在哪?
我们了解了一个进程的地址空间之后,是否会好奇,申请到的物理内存都存在哪了?可能很多人觉得,不就是物理内存吗?
我这里说申请的内存在哪,是因为物理内存有分为cache和普通物理内存,可以通过 free 命令查看,而且物理内存还有分 DMA,NORMAL,HIGH 三个区,这里主要分析cache和普通内存。
通过第一部分,我们知道一个进程的地址空间几乎都是 mmap 函数申请,有文件映射和匿名映射两种。
3.1 共享文件映射
我们先来看下代码段和动态链接库映射段,这两个都是属于共享文件映射,也就是说由同一个可执行文件启动的两个进程是共享这两个段,都是映射到同一块物理内存,那么这块内存在哪了?我写了个程序测试如下:


dd if=/dev/zero of=fileblock bs=M count=1024

3.2 私有文件映射段
对于进程空间中的数据段,其必须是私有文件映射,因为如果是共享文件映射,那么同一个可执行文件启动的两个进程,任何一个进程修改数据段,都将影响另一个进程了,我将上述测试程序改写成匿名文件映射:
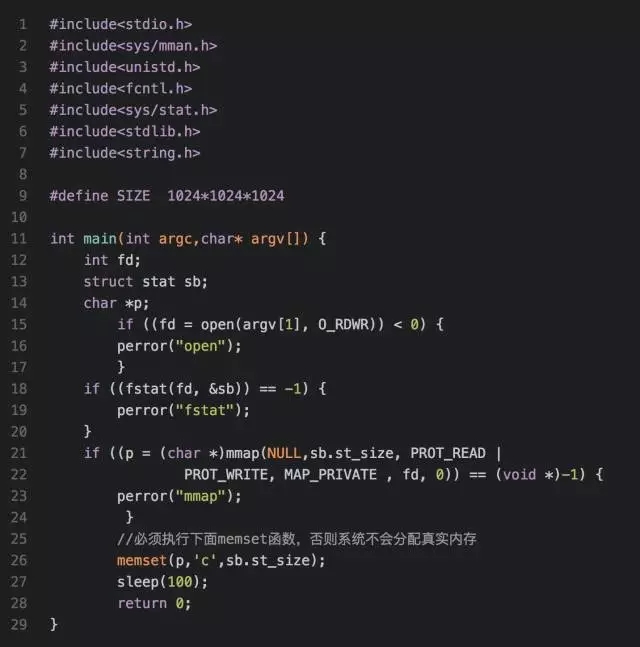
在执行程序执行,需要先将之前的 cache 释放掉,否则会影响结果
echo 1 >> /proc/sys/vm/drop_caches
接着执行程序,看下内存使用情况:
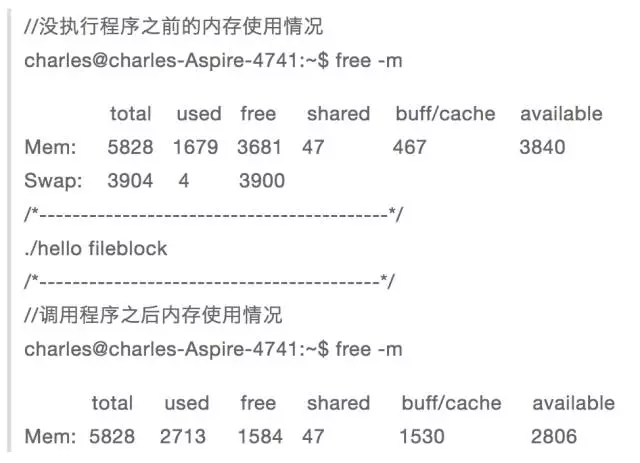
从使用前和使用后对比,可以发现 used 和 buff/cache 分别增长了1G,说明当进行私有文件映射时,首先是将文件映射到 cache 中,然后如果某个文件对这个文件进行修改,则会从其他内存中分配一块内存先将文件数据拷贝至新分配的内存,然后再在新分配的内存上进行修改,这也就是写时复制。
这也很好理解,因为如果同一个可执行文件开启多个实例,那么内核先将这个可执行的数据段映射到 cache,然后每个实例如果有修改数据段,则都将分配一个一块内存存储数据段,毕竟数据段也是一个进程私有的。
通过上述分析,可以得出结论,如果是文件映射,则都是将文件映射到 cache 中,然后根据共享还是私有进行不同的操作。
3.3 私有匿名映射

这时再来看下内存的使用情况

3.4 共享匿名映射
当我们需要在父子进程共享内存时,就可以用到 mmap 共享匿名映射,那么共享匿名映射的内存是存放在哪了?我继续改写上述测试程序为共享匿名映射 。

这时来看下内存的使用情况:

从上述结果,我们可以看出,只有buff/cache增长了1G,即当进行共享匿名映射时,这时是从 cache 中申请内存,道理也很明显,因为父子进程共享这块内存,共享匿名映射存在于 cache,然后每个进程再映射到彼此的虚存空间,这样即可操作的是同一块内存。
4、系统回收内存
当系统内存不足时,有两种方式进行内存释放,一种是手动的方式,另一种是系统自己触发的内存回收,先来看下手动触发方式。
4.1 手动回收内存
手动回收内存,之前也有演示过,即
echo 1 >> /proc/sys/vm/drop_caches
我们可以在 man proc 下面看到关于这个的简介
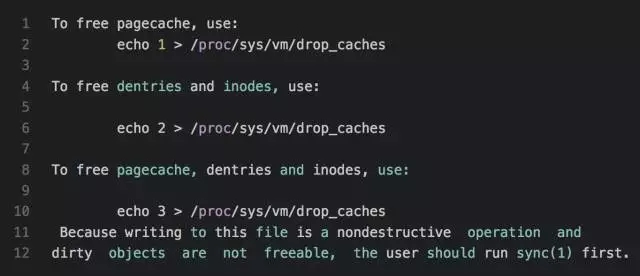
从这个介绍可以看出,当 drop_caches 文件为1时,这时将释放 pagecache 中可释放的部分(有些 cache 是不能通过这个释放的),当 drop_caches 为2时,这时将释放 dentries 和 inodes 缓存,当 drop_caches 为3时,这同时释放上述两项。
关键还有最后一句,意思是说如果 pagecache 中有脏数据时,操作 drop_caches 是不能释放的,必须通过 sync 命令将脏数据刷新到磁盘,才能通过操作 drop_caches 释放 pagecache。
ok,之前有提到有些pagecache是不能通过drop_caches释放的,那么除了上述提文件映射和共享匿名映射外,还有有哪些东西是存在pagecache了?
4.2 tmpfs
我们先来看下 tmpfs ,tmpfs 和 procfs,sysfs 以及 ramfs 一样,都是基于内存的文件系统,tmpfs 和 ramfs 的区别就是 ramfs 的文件基于纯内存的,和 tmpfs 除了纯内存外,还会使用 swap 交换空间,以及 ramfs 可能会把内存耗尽,而 tmpfs 可以限定使用内存大小,可以用命令 df -T -h 查看系统一些文件系统,其中就有一些是 tmpfs,比较出名的是目录 /dev/shm
tmpfs 文件系统源文件在内核源码 mm/shmem.c,tmpfs实现很复杂,之前有介绍虚拟文件系统,基于 tmpfs 文件系统创建文件和其他基于磁盘的文件系统一样,也会有 inode,super_block,identry,file 等结构,区别主要是在读写上,因为读写才涉及到文件的载体是内存还是磁盘。
而 tmpfs 文件的读函数 shmem_file_read,过程主要为通过 inode 结构找到 address_space 地址空间,其实就是磁盘文件的 pagecache,然后通过读偏移定位cache 页以及页内偏移。
这时就可以直接从这个 pagecache 通过函数 __copy_to_user 将缓存页内数据拷贝到用户空间,当我们要读物的数据不pagecache中时,这时要判断是否在 swap 中,如果在则先将内存页 swap in,再读取。
tmpfs 文件的写函数 shmem_file_write,过程主要为先判断要写的页是否在内存中,如果在,则直接将用户态数据通过函数__copy_from_user拷贝至内核pagecache中覆盖老数据,并标为 dirty。
如果要写的数据不再内存中,则判断是否在swap 中,如果在,则先读取出来,用新数据覆盖老数据并标为脏,如果即不在内存也不在磁盘,则新生成一个 pagecache 存储用户数据。
由上面分析,我们知道基于 tmpfs 的文件也是使用 cache 的,我们可以在/dev/shm上创建一个文件来检测下:

看到了吧,cache 增长了1G,验证了 tmpfs 的确使用的 cache 内存。
其实 mmap 匿名映射原理也是用了 tmpfs,在 mm/mmap.c->do_mmap_pgoff 函数内部,有判断如果 file 结构为空以及为 SHARED 映射,则调用 shmem_zero_setup(vma) 函数在 tmpfs 上用新建一个文件

这里就解释了为什么共享匿名映射内存初始化为0了,但是我们知道用 mmap 分配的内存初始化为0,就是说 mmap 私有匿名映射也为0,那么体现在哪了?
这个在 do_mmap_pgoff 函数内部可没有体现出来,而是在缺页异常,然后分配一种特殊的初始化为0的页。
那么这个 tmpfs 占有的内存页可以回收吗?

也就是说 tmpfs 文件占有的 pagecache 是不能回收的,道理也很明显,因为有文件引用这些页,就不能回收。
4.3 共享内存
posix 共享内存其实和 mmap 共享映射是同一个道理,都是利用在 tmpfs 文件系统上新建一个文件,然后再映射到用户态,最后两个进程操作同一个物理内存,那么 System V 共享内存是否也是利用 tmpfs 文件系统了?
我们可以跟踪到下述函数

这个函数就是新建一个共享内存段,其中函数
shmem_kernel_file_setup
就是在 tmpfs 文件系统上创建一个文件,然后通过这个内存文件实现进程通信,这我就不写测试程序了,而且这也是不能回收的,因为共享内存ipc机制生命周期是随内核的,也就是说你创建共享内存之后,如果不显示删除的话,进程退出之后,共享内存还是存在的。
之前看了一些技术博客,说到 Poxic 和 System V 两套 ipc 机制(消息队列,信号量以及共享内存)都是使用 tmpfs 文件系统,也就是说最终内存使用的都是 pagecache,但是我在源码中看出了两个共享内存是基于 tmpfs 文件系统,其他信号量和消息队列还没看出来(有待后续考究)。
posix 消息队列的实现有点类似与 pipe 的实现,也是自己一套 mqueue 文件系统,然后在 inode 上的 i_private 上挂上关于消息队列属性 mqueue_inode_info,在这个属性上,内核2.6时,是用一个数组存储消息,而到了4.6则用红黑树了存储消息(我下载了这两个版本,具体什么时候开始用红黑树,没深究)。
然后两个进程每次操作都是操作这个 mqueue_inode_info 中的消息数组或者红黑树,实现进程通信,和这个 mqueue_inode_info 类似的还有 tmpfs 文件系统属性shmem_inode_info 和为epoll服务的文件系统 eventloop,也有一个特殊属性struct eventpoll,这个是挂在 file 结构的 private_data 等等。
说到这,可以小结下,进程空间中代码段,数据段,动态链接库(共享文件映射),mmap 共享匿名映射都存在于 cache 中,但是这些内存页都有被进程引用,所以是不能释放的,基于 tmpfs 的 ipc 进程间通信机制的生命周期是随内核,因此也是不能通过 drop_caches 释放。
虽然上述提及的cache不能释放,但是后面有提到,当内存不足时,这些内存是可以 swap out 的。
因此 drop_caches 能释放的就是当从磁盘读取文件时的缓存页以及某个进程将某个文件映射到内存之后,进程退出,这时映射文件的的缓存页如果没有被引用,也是可以被释放的。
4.4 内存自动释放方式
当系统内存不够时,操作系统有一套自我整理内存,并尽可能的释放内存机制,如果这套机制不能释放足够多的内存,那么只能 OOM 了。
之前在提及 OOM 时,说道 redis 因为 OOM 被杀死,如下:

第二句后半部分,
total-vm:186660kB, anon-rss:9388kB, file-rss:4kB
把一个进程内存使用情况,用三个属性进行了说明,即所有虚拟内存,常驻内存匿名映射页以及常驻内存文件映射页。
其实从上述的分析,我们也可以知道一个进程其实就是文件映射和匿名映射:
文件映射:代码段,数据段,动态链接库共享存储段以及用户程序的文件映射段;
匿名映射:bbs段,堆,以及当 malloc 用 mmap 分配的内存,还有mmap共享内存段;
其实内核回收内存就是根据文件映射和匿名映射来进行的,在 mmzone.h 有如下定义:
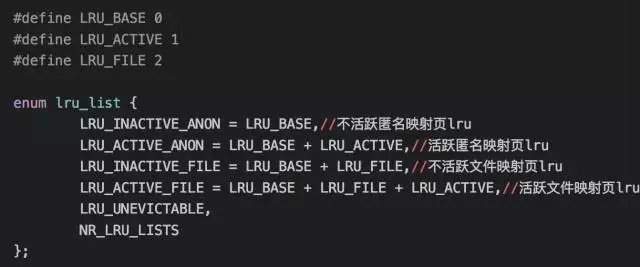
LRU_UNEVICTABLE 即为不可驱逐页 lru,我的理解就是当调用 mlock 锁住内存,不让系统 swap out 出去的页列表。
简单说下 linux 内核自动回收内存原理,内核有一个 kswapd 会周期性的检查内存使用情况,如果发现空闲内存定于 pages_low,则 kswapd 会对 lru_list 前四个 lru 队列进行扫描,在活跃链表中查找不活跃的页,并添加不活跃链表。
然后再遍历不活跃链表,逐个进行回收释放出32个页,知道 free page 数量达到 pages_high,针对不同的页,回收方式也不一样。
当然,当内存水平低于某个极限阈值时,会直接发出内存回收,原理和 kswapd 一样,但是这次回收力度更大,需要回收更多的内存。
文件页:
如果是脏页,则直接回写进磁盘,再回收内存。
如果不是脏页,则直接释放回收,因为如果是io读缓存,直接释放掉,下次读时,缺页异常,直接到磁盘读回来即可,如果是文件映射页,直接释放掉,下次访问时,也是产生两个缺页异常,一次将文件内容读取进磁盘,另一次与进程虚拟内存关联。
匿名页:因为匿名页没有回写的地方,如果释放掉,那么就找不到数据了,所以匿名页的回收是采取 swap out 到磁盘,并在页表项做个标记,下次缺页异常在从磁盘 swap in 进内存。
swap 换进换出其实是很占用系统IO的,如果系统内存需求突然间迅速增长,那么cpu 将被io占用,系统会卡死,导致不能对外提供服务,因此系统提供一个参数,用于设置当进行内存回收时,执行回收 cache 和 swap 匿名页的,这个参数为:

意思就是说这个值越高,越可能使用 swap 的方式回收内存,最大值为100,如果设为0,则尽可能使用回收 cache 的方式释放内存。